
We are excited to announce the release of PyTorch® 2.0 which we highlighted during the PyTorch Conference on 12/2/22! PyTorch 2.0 offers the same eager-mode development and user experience, while fundamentally changing and supercharging how PyTorch operates at compiler level under the hood with faster performance and support for Dynamic Shapes and Distributed.
This next-generation release includes a Stable version of Accelerated Transformers (formerly called Better Transformers); Beta includes torch.compile as the main API for PyTorch 2.0, the scaled_dot_product_attention function as part of torch.nn.functional, the MPS backend, functorch APIs in the torch.func module; and other Beta/Prototype improvements across various inferences, performance and training optimization features on GPUs and CPUs. For a comprehensive introduction and technical overview of torch.compile, please visit the 2.0 Get Started page.
Along with 2.0, we are also releasing a series of beta updates to the PyTorch domain libraries, including those that are in-tree, and separate libraries including TorchAudio, TorchVision, and TorchText. An update for TorchX is also being released as it moves to community supported mode. More details can be found in this library blog.
This release is composed of over 4,541 commits and 428 contributors since 1.13.1. We want to sincerely thank our dedicated community for your contributions. As always, we encourage you to try these out and report any issues as we improve 2.0 and the overall 2-series this year.
Summary:
- torch.compile is the main API for PyTorch 2.0, which wraps your model and returns a compiled model. It is a fully additive (and optional) feature and hence 2.0 is 100% backward compatible by definition.
- As an underpinning technology of torch.compile, TorchInductor with Nvidia and AMD GPUs will rely on OpenAI Triton deep learning compiler to generate performant code and hide low level hardware details. OpenAI Triton-generated kernels achieve performance that’s on par with hand-written kernels and specialized cuda libraries such as cublas.
- Accelerated Transformers introduce high-performance support for training and inference using a custom kernel architecture for scaled dot product attention (SPDA). The API is integrated with torch.compile() and model developers may also use the scaled dot product attention kernels directly by calling the new scaled_dot_product_attention() operator.
- Metal Performance Shaders (MPS) backend provides GPU accelerated PyTorch training on Mac platforms with added support for Top 60 most used ops, bringing coverage to over 300 operators.
- Amazon AWS optimizes the PyTorch CPU inference on AWS Graviton3 based C7g instances. PyTorch 2.0 improves inference performance on Graviton compared to the previous releases, including improvements for Resnet50 and Bert.
- New prototype features and technologies across TensorParallel, DTensor, 2D parallel, TorchDynamo, AOTAutograd, PrimTorch and TorchInductor.
*To see a full list of public 2.0, 1.13 and 1.12 feature submissions click here.
STABLE FEATURES
[Stable] Accelerated PyTorch 2 Transformers
The PyTorch 2.0 release includes a new high-performance implementation of the PyTorch Transformer API. In releasing Accelerated PT2 Transformers, our goal is to make training and deployment of state-of-the-art Transformer models affordable across the industry. This release introduces high-performance support for training and inference using a custom kernel architecture for scaled dot product attention (SPDA), extending the inference “fastpath” architecture, previously known as “Better Transformer.”
Similar to the “fastpath” architecture, custom kernels are fully integrated into the PyTorch Transformer API – thus, using the native Transformer and MultiHeadAttention API will enable users to:
- transparently see significant speed improvements;
- support many more use cases including models using Cross-Attention, Transformer Decoders, and for training models; and
- continue to use fastpath inference for fixed and variable sequence length Transformer Encoder and Self Attention use cases.
To take full advantage of different hardware models and Transformer use cases, multiple SDPA custom kernels are supported (see below), with custom kernel selection logic that will pick the highest-performance kernel for a given model and hardware type. In addition to the existing Transformer API, model developers may also use the scaled dot product attention kernels directly by calling the new scaled_dot_product_attention() operator. Accelerated PyTorch 2 Transformers are integrated with torch.compile() . To use your model while benefiting from the additional acceleration of PT2-compilation (for inference or training), pre-process the model with model = torch.compile(model).
We have achieved major speedups for training transformer models and in particular large language models with Accelerated PyTorch 2 Transformers using a combination of custom kernels and torch.compile().
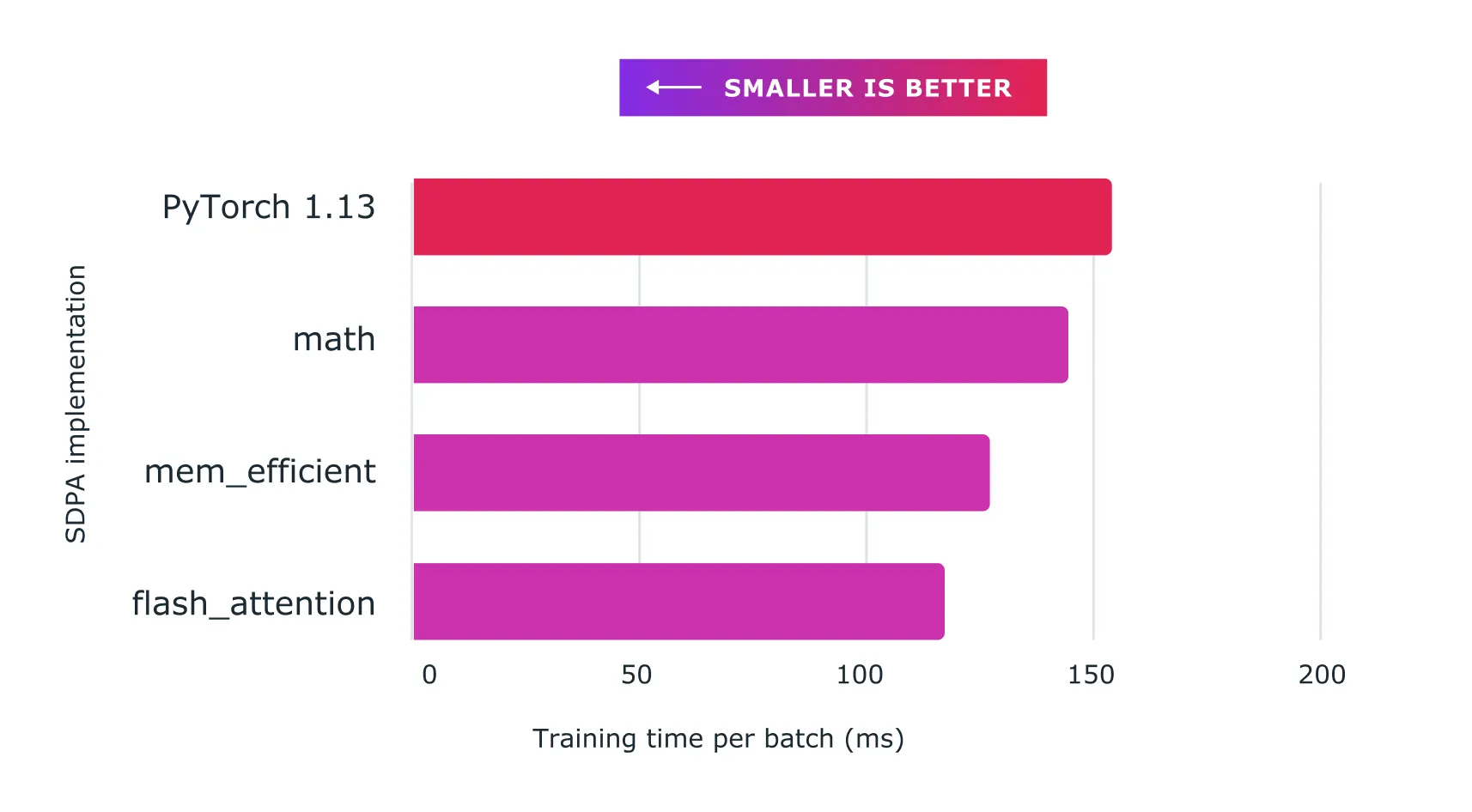 Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for nanoGPT shown here.
Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for nanoGPT shown here.
BETA FEATURES
[Beta] torch.compile
torch.compile is the main API for PyTorch 2.0, which wraps your model and returns a compiled model. It is a fully additive (and optional) feature and hence 2.0 is 100% backward compatible by definition.
Underpinning torch.compile are new technologies – TorchDynamo, AOTAutograd, PrimTorch and TorchInductor:
- TorchDynamo captures PyTorch programs safely using Python Frame Evaluation Hooks and is a significant innovation that was a result of 5 years of our R&D into safe graph capture.
- AOTAutograd overloads PyTorch’s autograd engine as a tracing autodiff for generating ahead-of-time backward traces.
- PrimTorch canonicalizes ~2000+ PyTorch operators down to a closed set of ~250 primitive operators that developers can target to build a complete PyTorch backend. This substantially lowers the barrier of writing a PyTorch feature or backend.
- TorchInductor is a deep learning compiler that generates fast code for multiple accelerators and backends. For NVIDIA and AMD GPUs, it uses OpenAI Triton as a key building block. For intel CPUs, we generate C++ code using multithreading, vectorized instructions and offloading appropriate operations to mkldnn when possible.
With all the new technologies, torch.compile is able to work 93% of time across 165 open-source models and runs 20% faster on average at float32 precision and 36% faster on average at AMP precision.
For more information, please refer to https://pytorch.org/get-started/pytorch-2.0/ and for TorchInductor CPU with Intel here.
[Beta] PyTorch MPS Backend
MPS backend provides GPU-accelerated PyTorch training on Mac platforms. This release brings improved correctness, stability, and operator coverage.
MPS backend now includes support for the Top 60 most used ops, along with the most frequently requested operations by the community, bringing coverage to over 300 operators. The major focus of the release was to enable full OpInfo-based forward and gradient mode testing to address silent correctness issues. These changes have resulted in wider adoption of MPS backend by 3rd party networks such as Stable Diffusion, YoloV5, WhisperAI, along with increased coverage for Torchbench networks and Basic tutorials. We encourage developers to update to the latest macOS release to see the best performance and stability on the MPS backend.
Links
- MPS Backend
- Developer information
- Accelerated PyTorch training on Mac
- Metal, Metal Performance Shaders & Metal Performance Shaders Graph
[Beta] Scaled dot product attention 2.0
We are thrilled to announce the release of PyTorch 2.0, which introduces a powerful scaled dot product attention function as part of torch.nn.functional. This function includes multiple implementations that can be seamlessly applied depending on the input and hardware in use.
In previous versions of PyTorch, you had to rely on third-party implementations and install separate packages to take advantage of memory-optimized algorithms like FlashAttention. With PyTorch 2.0, all these implementations are readily available by default.
These implementations include FlashAttention from HazyResearch, Memory-Efficient Attention from the xFormers project, and a native C++ implementation that is ideal for non-CUDA devices or when high-precision is required.
PyTorch 2.0 will automatically select the optimal implementation for your use case, but you can also toggle them individually for finer-grained control. Additionally, the scaled dot product attention function can be used to build common transformer architecture components.
Learn more with the documentation and this tutorial.
[Beta] functorch -> torch.func
Inspired by Google JAX, functorch is a library that offers composable vmap (vectorization) and autodiff transforms. It enables advanced autodiff use cases that would otherwise be tricky to express in PyTorch. Examples include:
- model ensembling
- efficiently computing jacobians and hessians
- computing per-sample-gradients (or other per-sample quantities)
We’re excited to announce that, as the final step of upstreaming and integrating functorch into PyTorch, the functorch APIs are now available in the torch.func module. Our function transform APIs are identical to before, but we have changed how the interaction with NN modules work. Please see the docs and the migration guide for more details.
Furthermore, we have added support for torch.autograd.Function: one is now able to apply function transformations (e.g. vmap, grad, jvp) over torch.autograd.Function.
[Beta] Dispatchable Collectives
Dispatchable collectives is an improvement to the existing init_process_group() API which changes backend to an optional argument. For users, the main advantage of this feature is that it will allow them to write code that can run on both GPU and CPU machines without having to change the backend specification. The dispatchability feature will also make it easier for users to support both GPU and CPU collectives, as they will no longer need to specify the backend manually (e.g. “NCCL” or “GLOO”). Existing backend specifications by users will be honored and will not require change.
Usage example:
import torch.distributed.dist
…
# old
dist.init_process_group(backend=”nccl”, ...)
dist.all_reduce(...) # with CUDA tensors works
dist.all_reduce(...) # with CPU tensors does not work
# new
dist.init_process_group(...) # backend is optional
dist.all_reduce(...) # with CUDA tensors works
dist.all_reduce(...) # with CPU tensors works
Learn more here.
[Beta] torch.set_default_device and torch.device as context manager
torch.set_default_device allows users to change the default device that factory functions in PyTorch allocate on. For example, if you torch.set_default_device(‘cuda’), a call to torch.empty(2) will allocate on CUDA (rather than on CPU). You can also use torch.device as a context manager to change the default device on a local basis. This resolves a long standing feature request from PyTorch’s initial release for a way to do this.
Learn more here.


