
Harry (Lei) Zhang, together with the CTO of HyperHQ, Xu Wang, will present “CRI: The Second Boom of Container Runtimes” at KubeCon + CloudNativeCon EU 2018, May 2-4 in Copenhagen, Denmark. The presentation will clarify about more about CRI, container runtimes, KataContainers and where they are going. Please join them if you are interested in learning more.
When was the first “boom” of container runtimes in your mind?
Harry (Lei) Zhang: At the end of 2013, one of my former colleagues at an extremely successful cloud computing company introduced me to a small project on Github, and claimed: “this thing’s gonna kill us.”
We all know the rest of the story. Docker started a revolution in containers, which soon swept the whole world with its slogan of “Build, Ship, Run.” The brilliant idea of the Docker image reconstructed the base of cloud computing by changing the way software was delivered, and how developers consumed the cloud. The following years of 2014-2015 were all dominated by the word container it was hot and fancy, and swept through all the companies in the industry, just like AI today.
What happened to container runtimes after that?
Zhang: After this period of prosperity, container runtimes, of course including Docker, gradually became a secondary issue. Instead, people were more eager to quarrel over container scheduling and orchestration, which eventually brought Kubernetes to the center of the container world. This is not surprising, although the container itself is highly creative, once it is separated from the upper-level orchestration framework, the significance of this innovation is be greatly reduced. This also explains why CNCF, which is led by platform players like Google and Red Hat, eventually became the winner of the dispute: container runtimes are “boring”.
So you are claiming a new prosperity comes for container runtimes now?
Zhang: Yes. In 2017, the Kubernetes community, started pushing container runtimes back to the forefront with projects like cri-o, containerd, Kata, frakti –
In fact, this second boom is no longer because of the technological competition, but because of the birth of a generic Container Runtime Interface (CRI), which leveraged the freedom to develop container runtimes for Kubernetes however they wanted, using whatever technology. This is further evidence that Kubernetes is winning the infrastructure software industry.
Could you please explain more about CRI?
Zhang: The creation of CRI can be dated back to a pretty old issue in the Kubernetes repo, which, thanks to Brendan Burns and Dawn Chen brought out the idea of “client server mode container runtime.” The reason we began to discuss this approach in sig-node was mainly because, although Docker was the most successful container runtime at that time (and even today), we could see it gradually evolving to a much more complicated platform project, which brought uncertainty to Kubernetes itself. At the same time, new candidates like CoreOS rkt and Hyper runV (hypervisor based container) had been introduced in Kubernetes as PoC runtimes, and to bring extra maintenance efforts to sig-node. We needed to find a way to balance user options and feasibility in Kubernetes container runtimes, and to save users from any potential vendor lock in this layer.
What does CRI look like from a developer view?
Zhang: The core idea of CRI is simple: can we summarize a limited group of APIs which Kubernetes can rely on to talk to containers and images, regardless of what container runtime it is using?
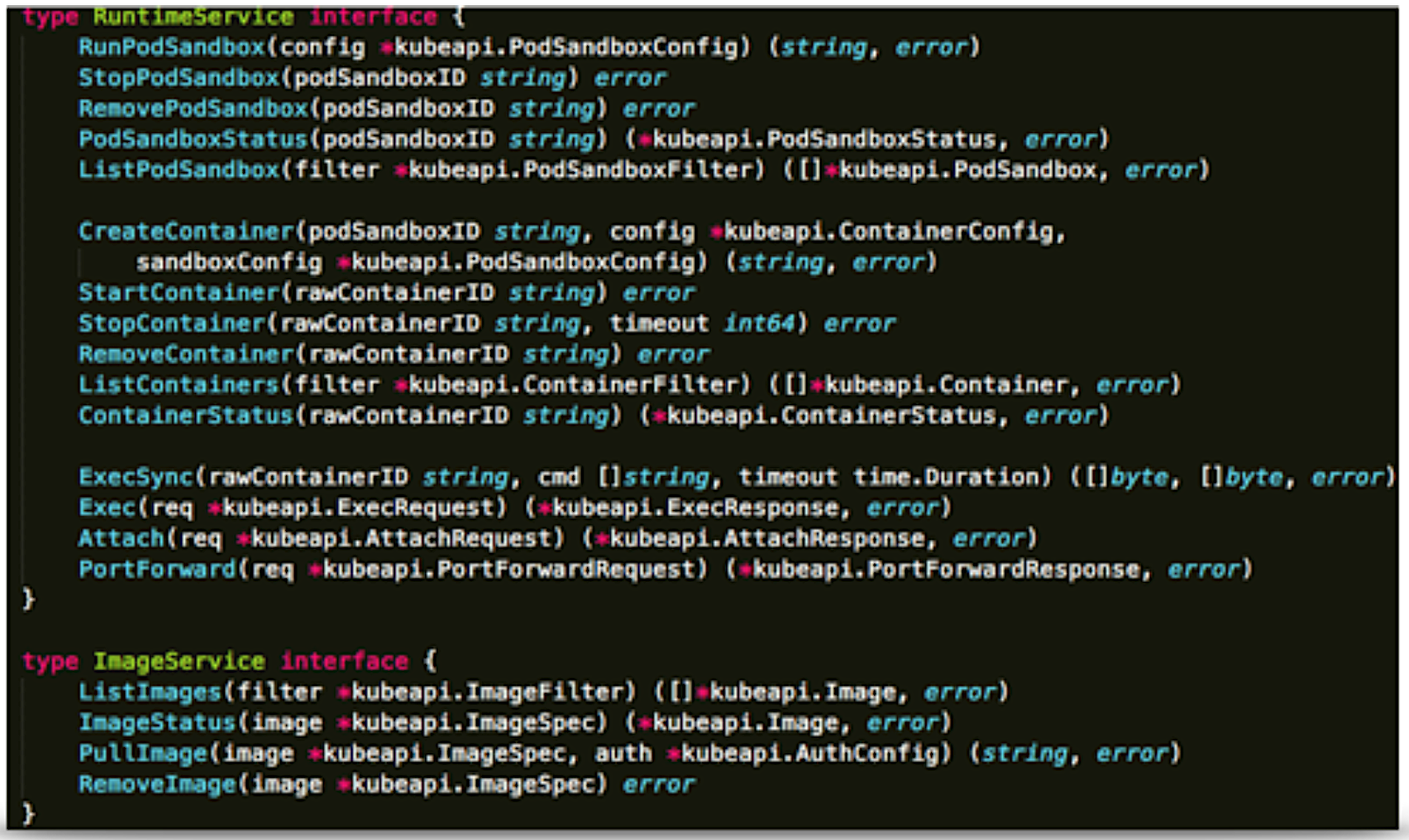
Sig-node eventually defined around 20 APIs in protoc format based on the existing operations in kubelet (the component that talks to container runtime in Kubernetes). If you are familiar with Docker, you can see that we indeed extracted the most frequently used APIs out from its CLI, and also defined the concept of “sandbox” to match to Pod in Kubernetes, which is a group of tightly coupled user containers. But the key is that once you have this interface, you now have the freedom to choose how to implement this “sandbox,” either by namespaces (Docker), or hypervisor (Kata). Soon after the CRI spec was ready, we worked together to deliver the first CRI implementation named “dockershim” for Docker, and then “frakti” for hypervisor runtimes (at that time, runV).
How does CRI work with Kubernetes?

Zhang: The core implementation of CRI is a GenericRuntime, which will hide CRI from kubelet so, from the Kubernetes side, it does not know about CRI or any container runtime. All the container and image operations will be called GenericRuntime just like it is in Docker or rkt.
The container functionalities, like networking and storage, are decoupled from container runtime by standard interfaces like CNI (Container Network Interface), and CSI (Container Storage Interface). Thus, the implementation of CRI (e.g. dockershim) will be able to call standard CNI interfaces to allocate the network for the target container without knowing any detail of underlying network plugins. The allocation result,will be returned back to kubelet after the CRI call
What’s more, the latest design of hardware accelerators in Kubernetes, like GPU and FPGA, also rely on CRI to allocate devices to corresponding containers. The core idea of this design is included in another extension system named Device Plugin. It is responsible for generating device information and dependency directories per device allocate request, and then returns them to kubelet. Again, Kubelet will inject this information into CRI to create a container call. That’s also the secret why the latest Kubernetes implementations do not rely on Docker, or any other specific container runtime to manage GPU, etc.
What are CRI shims? I’ve been hearing this a lot recently.
Zhang: Actually, CRI implementations are called CRI shims within the Kubernetes community. It is free for the developer to decide how to implement those CRI interfaces, and this has triggered another innovation storm at the container runtime level, which was almost forgotten by the community in recent years.
The most straightforward idea is: can I just implement a shim for runC, which is the building block for an existing Docker project? Of course yes. Not very long after CRI is released, maintainers of the runC project proposed a design which leverages users of Kubernetes to run workloads on runC without installing Docker at all. That project is cri-o.
Unlike Docker, cri-o is much simpler and only focuses on the container and image management, as well as serving CRI requests. Specifically, it “implements CRI using OCI conformant runtimes” (runC for example), so the scope of cri-o is always tied to the scope of the CRI. Besides a very basic CLI, cri-o will not expect users to use it the same way as Docker.
Besides these Linux operating system level containers (mostly based on cgroups and namespaces), we can also implement CRI by using hardware virtualization to achieve higher level security and isolation. These efforts rely on the newly created project KataContainers and corresponding CRI shim frakti.
The CRI has been so successful that many other container projects or legacy container runtimes are beginning to provide implementations for it. Alibaba’s internal container Pouch, for example, is a container runtime which has been used inside Alibaba for years, tested with unbelievable battles like serving the 1.48 billion transactions in 24-hours during the the Single’s Day (11/11) sale.
What’s the next direction of CRI and container runtimes in Kubernetes?
Zhang: I believe the second boom of container runtimes is still continuing, but this time, it is being lead by the Kubernetes community.
At the end of 2017, Intel ClearContainer and Hyper runV were announced to merge to one new project, KataContainers, under the governance of the OpenStack foundation and OCI. Those two teams are well known for leading the effort of pushing hypervisor based container runtimes to Kubernetes since 2015, and finally joined forces with the help of CRI.
This will not be the only story in this area. The maintainers of container runtimes have noticed that expressing their capabilities through Kubernetes, rather than competition at the container runtime level, is an effective way to promote the success of these projects. This has already been proven by cri-o, which is now a core component in Red Hat’s container portfolio, and is known for its simplicity and better performance. There’s no need to mention Windows Container with CRI support, which has already been promoted a high priority task in sig-node.
But there’s also concern. With the continuing of container runtime innovation, users now have to face the same problem again: which container runtime should I choose?
Luckily, this problem has already been partially solved by Kubernetes itself as it’s the Kubernetes API that users need to care about, not the container runtimes. But even for people who do not rely on Kubernetes, there is still a choice to be made. “No default” should be the “official” attitude from Kubernetes maintainers. One good thing is that we can see the maintainers of runtimes are trying their best to eliminate unnecessary burden for users. runV has merged with ClearContainer, and frakti will be refactored to containerd based eventually. After all, as a user of Kubernetes, I expect a future that only several container runtimes with essential differences for me to choose, if that’s the case, my life will be much easier.

Harry (Lei) Zhang, Engineer at HyperHQ, Microsoft MVP of cloud computing. Feature maintainer of Kubernetes project. Harry (Lei) Zhang mainly works on scheduling, CRI and hypervisor-based container runtime, i.e. KataContainers. Focusing on kube-scheduler, kubelet and secure container runtime on Kubernetes upstream as well as Hypernetes project. An active community advocator, tech speaker of LinuxCon, KubeCon, OpenStack Summit etc. Once published the book “Docker and Kubernetes Under The Hood” which is the best seller of container cloud area in China.
Learn more at KubeCon + CloudNativeCon Europe, coming up May 2-4 in Copenhagen, Denmark.





{kind=link}