
By Ashley Davis
*This article was originally published at TheNewStack
Applications built on microservices can be scaled in multiple ways. We can scale them to support development by larger development teams and we can also scale them up for better performance. Our application can then have a higher capacity and can handle a larger workload.
Using microservices gives us granular control over the performance of our application. We can easily measure the performance of our microservices to find the ones that are performing poorly, are overworked, or are overloaded at times of peak demand. Figure 1 shows how we might use the Kubernetes dashboard to understand CPU and memory usage for our microservices.

Figure 1: Viewing CPU and memory usage for microservices in the Kubernetes dashboard
If we were using a monolith, however, we would have limited control over performance. We could vertically scale the monolith, but that’s basically it.
Horizontally scaling a monolith is much more difficult; and we simply can’t independently scale any of the “parts” of a monolith. This isn’t ideal, because it might only be a small part of the monolith that causes the performance problem. Yet, we would have to vertically scale the entire monolith to fix it. Vertically scaling a large monolith can be an expensive proposition.
Instead, with microservices, we have numerous options for scaling. For instance, we can independently fine-tune the performance of small parts of our system to eliminate bottlenecks and achieve the right mix of performance outcomes.
There are also many advanced ways we could tackle performance issues, but in this post, we’ll overview a handful of relatively simple techniques for scaling our microservices using Kubernetes:
- Vertically scaling the entire cluster
- Horizontally scaling the entire cluster
- Horizontally scaling individual microservices
- Elastically scaling the entire cluster
- Elastically scaling individual microservices
Scaling often requires risky configuration changes to our cluster. For this reason, you shouldn’t try to make any of these changes directly to a production cluster that your customers or staff are depending on.
Instead, I would suggest that you create a new cluster and use blue-green deployment, or a similar deployment strategy, to buffer your users from risky changes to your infrastructure.
Vertically Scaling the Cluster
As we grow our application, we might come to a point where our cluster generally doesn’t have enough compute, memory or storage to run our application. As we add new microservices (or replicate existing microservices for redundancy), we will eventually max out the nodes in our cluster. (We can monitor this through our cloud vendor or the Kubernetes dashboard.)
At this point, we must increase the total amount of resources available to our cluster. When scaling microservices on a Kubernetes cluster, we can just as easily make use of either vertical or horizontal scaling. Figure 2 shows what vertical scaling looks like for Kubernetes.

Figure 2: Vertically scaling your cluster by increasing the size of the virtual machines (VMs)
We scale up our cluster by increasing the size of the virtual machines (VMs) in the node pool. In this example, we increased the size of three small-sized VMs so that we now have three large-sized VMs. We haven’t changed the number of VMs; we’ve just increased their size — scaling our VMs vertically.
Listing 1 is an extract from Terraform code that provisions a cluster on Azure; we change the vm_size field from Standard_B2ms to Standard_B4ms. This upgrades the size of each VM in our Kubernetes node pool. Instead of two CPUs, we now have four (one for each VM). As part of this change, memory and hard-drive for the VM also increase. If you are deploying to AWS or GCP, you can use this technique to vertically scale, but those cloud platforms offer different options for varying VM sizes.
We still only have a single VM in our cluster, but we have increased our VM’s size. In this example, scaling our cluster is as simple as a code change. This is the power of infrastructure-as-code, the technique where we store our infrastructure configuration as code and make changes to our infrastructure by committing code changes that trigger our continuous delivery (CD) pipeline

Listing 1: Vertically scaling the cluster with Terraform (an extract)
Horizontally Scaling the Cluster
In addition to vertically scaling our cluster, we can also scale it horizontally. Our VMs can remain the same size, but we simply add more VMs.
By adding more VMs to our cluster, we spread the load of our application across more computers. Figure 3 illustrates how we can take our cluster from three VMs up to six. The size of each VM remains the same, but we gain more computing power by having more VMs.
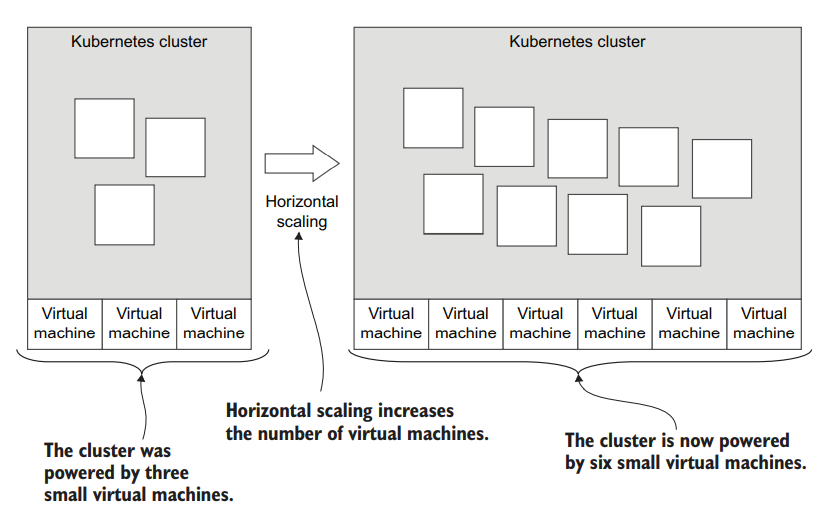
Figure 3: Horizontally scaling your cluster by increasing the number of VMs
Listing 2 shows an extract of Terraform code to add more VMs to our node pool. Back in listing 1, we had node_count set to 1, but here we have changed it to 6. Note that we reverted the vm_size field to the smaller size of Standard_B2ms. In this example, we increase the number of VMs, but not their size; although there is nothing stopping us from increasing both the number and the size of our VMs.
Generally, though, we might prefer horizontal scaling because it is less expensive than vertical scaling. That’s because using many smaller VMs is cheaper than using fewer but bigger and higher-priced VMs.

Listing 2: Horizontal scaling the cluster with Terraform (an extract)
Horizontally Scaling an Individual Microservice
Assuming our cluster is scaled to an adequate size to host all the microservices with good performance, what do we do when individual microservices become overloaded? (This can be monitored in the Kubernetes dashboard.)
Whenever a microservice becomes a performance bottleneck, we can horizontally scale it to distribute its load over multiple instances. This is shown in figure 4.
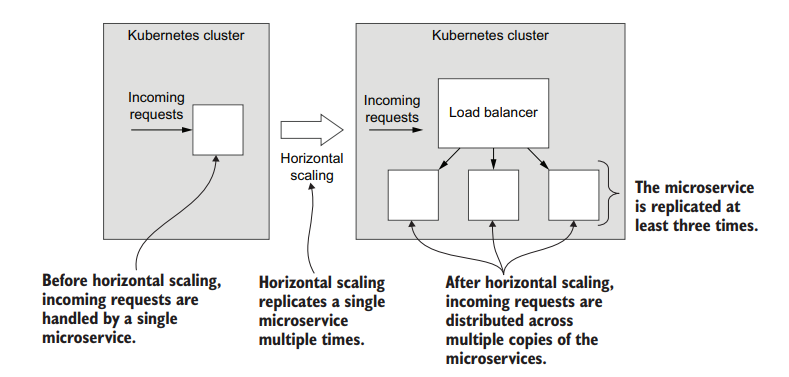
Figure 4: Horizontally scaling a microservice by replicating it
We are effectively giving more compute, memory and storage to this particular microservice so that it can handle a bigger workload.
Again, we can use code to make this change. We can do this by setting the replicas field in the specification for our Kubernetes deployment or pod as shown in listing 3.

Listing 3: Horizontally scaling a microservice with Terraform (an extract)
Not only can we scale individual microservices for performance, we can also horizontally scale our microservices for redundancy, creating a more fault-tolerant application. By having multiple instances, there are others available to pick up the load whenever any single instance fails. This allows the failed instance of a microservice to restart and begin working again.
Elastic Scaling for the Cluster
Moving into more advanced territory, we can now think about elastic scaling. This is a technique where we automatically and dynamically scale our cluster to meet varying levels of demand.
Whenever a demand is low, Kubernetes can automatically deallocate resources that aren’t needed. During high-demand periods, new resources are allocated to meet the increased workload. This generates substantial cost savings because, at any given moment, we only pay for the resources necessary to handle our application’s workload at that time.
We can use elastic scaling at the cluster level to automatically grow our clusters that are nearing their resource limits. Yet again, when using Terraform, this is just a code change. Listing 4 shows how we can enable the Kubernetes autoscaler and set the minimum and maximum size of our node pool.
Elastic scaling for the cluster works by default, but there are also many ways we can customize it. Search for “auto_scaler_profile” in the Terraform documentation to learn more.

Listing 4: Enabling elastic scaling for the cluster with Terraform (an extract)
Elastic Scaling for an Individual Microservice
We can also enable elastic scaling at the level of an individual microservice.
Listing 5 is a sample of Terraform code that gives microservices a “burstable” capability. The number of replicas for the microservice is expanded and contracted dynamically to meet the varying workload for the microservice (bursts of activity).
The scaling works by default, but can be customized to use other metrics. See the Terraform documentation to learn more. To learn more about pod auto-scaling in Kubernetes, see the Kubernetes docs.

Listing 5: Enabling elastic scaling for a microservice with Terraform
About the Book: Bootstrapping Microservices
You can learn about building applications with microservices with Bootstrapping Microservices.
Bootstrapping Microservices is a practical and project-based guide to building applications with microservices. It will take you all the way from building one single microservice all the way up to running a microservices application in production on Kubernetes, ending up with an automated continuous delivery pipeline and using infrastructure-as-code to push updates into production.
Other Kubernetes Resources
This post is an extract from Bootstrapping Microservices and has been a short overview of the ways we can scale microservices when running them on Kubernetes.
We specify the configuration for our infrastructure using Terraform. Creating and updating our infrastructure through code in this way is known as intrastructure-as-code, as a technique that turns working with infrastructure into a coding task and paved the way for the DevOps revolution.
To learn more about Kubernetes, please see the Kubernetes documentation and the free Introduction to Kubernetes training course.
To learn more about working with Kubernetes using Terraform, please see the Terraform documentation.
The post Scaling Microservices on Kubernetes appeared first on Linux Foundation – Training.
 + Bonus Savings on IT Professional Programs")
