So, where does Linux go next? After covering Linux for almost all 29 years of its history and knowing pretty much anyone who’s anyone in Linux development circles, up to and including Linus Torvalds, I think I have a clue.
We’d like an easy way to judge open-source programs. It can be done. But easily? That’s another matter. When it comes to open source, you can’t rely on star power.
The “wisdom of the crowd” has inspired all sorts of online services wherein people share their opinions and guide others in making choices. The Internet community has created many ways to do this, such as Amazon reviews, Glassdoor (where you can rate employers), and TripAdvisor and Yelp (for hotels, restaurants, and other service providers). You can rate or recommend commercial software, too, such as on mobile app stores or through sites like product hunt. But if you want advice to help you choose open-source applications, the results are disappointing.
It isn’t for lack of trying. Plenty of people have created systems to collect, judge, and evaluate open-source projects, including information about a project’s popularity, reliability, and activity. But each of those review sites – and their methodologies – have flaws.
The rise of open cloud platforms is fostering a rise in demand for Linux specialists equipped with the right expertise. In this new environment, obtaining a Linux certification can boost your career by proving your skills in increasingly critical areas.
With the vast majority of Amazon servers running Linux, and many servers running open-source software, Linux is, in the eyes of many, the de facto OS of the cloud. No wonder sysadmins, systems engineers, and system administrators with Linux skills can earn a healthy salary premium.
The Linux Foundation and Cloud Native Computing Foundation have released a new, free training course, Introduction to Serverless on Kubernetes, on the edX platform. The course explains how to build serverless functions that can run on any cloud, without being restricted by limits on the execution duration, languages available, or the size of your code. It is designed to provide an overview of how a serverless approach works in tandem with a Kubernetes cluster.
There are many business reasons to use open source software. Many of today’s most significant business breakthroughs, including big data, machine learning, cloud computing, Internet of Things, and streaming analytics, sprang from open source software innovations. Open source software often comes into an organization as the backbone of many essential devices, programs, platforms, and tools such as robotics, sensors, the Internet of Things (IoT), automotive telematics, and autonomous driving, edge computing, and big data computing. Open source software code is working on many smartphones, laptops, servers, databases, and cloud infrastructures and services. Developers build most applications by leveraging frameworks like Node. js or pulling in libraries that have been tested and proven in many production use cases. To use almost any of these things is to use open source software in one form or another, and often in combination.
By using open source software, companies also avoid building everything from the ground up, saving time, money, and effort while also rendering more innovation from the investment. Open source software is generally more secure than using the commercial proprietary counterparts too. That is due in large part to the collaborative nature of open source software projects. A common phrase used by Open Source developers and advocates is that “given enough eyeballs, all bugs are shallow.” That holds so long as there are “enough eyeballs,” which, given open source software’s adoption rate, may be challenging to have across all projects. Drawbacks do exist, as no software is perfect, not even open source software. However, for most organizations, the good far outweighs the bad. The codebase’s open nature also means it’s easier to report and fix software versus alternative models.
While open source software offers many reliable and provable business advantages, sometimes those advantages remain obscure to those who have not looked deeply into the topic, including many high-level decision-makers. This paper, published by the European Chapter of the TODO Group, aims to provide a balanced and quick overview of the business pros and cons of using open source software.
To download Why Open Source Matters to Your Enterprise click on the button below
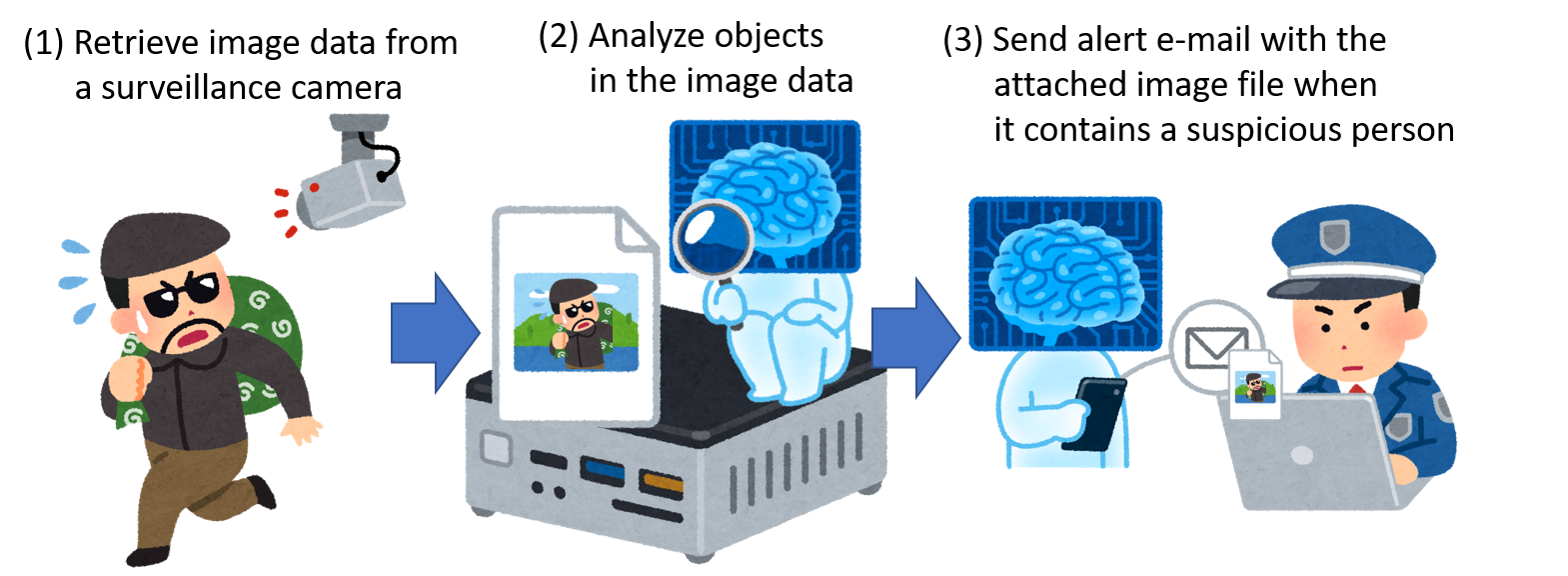
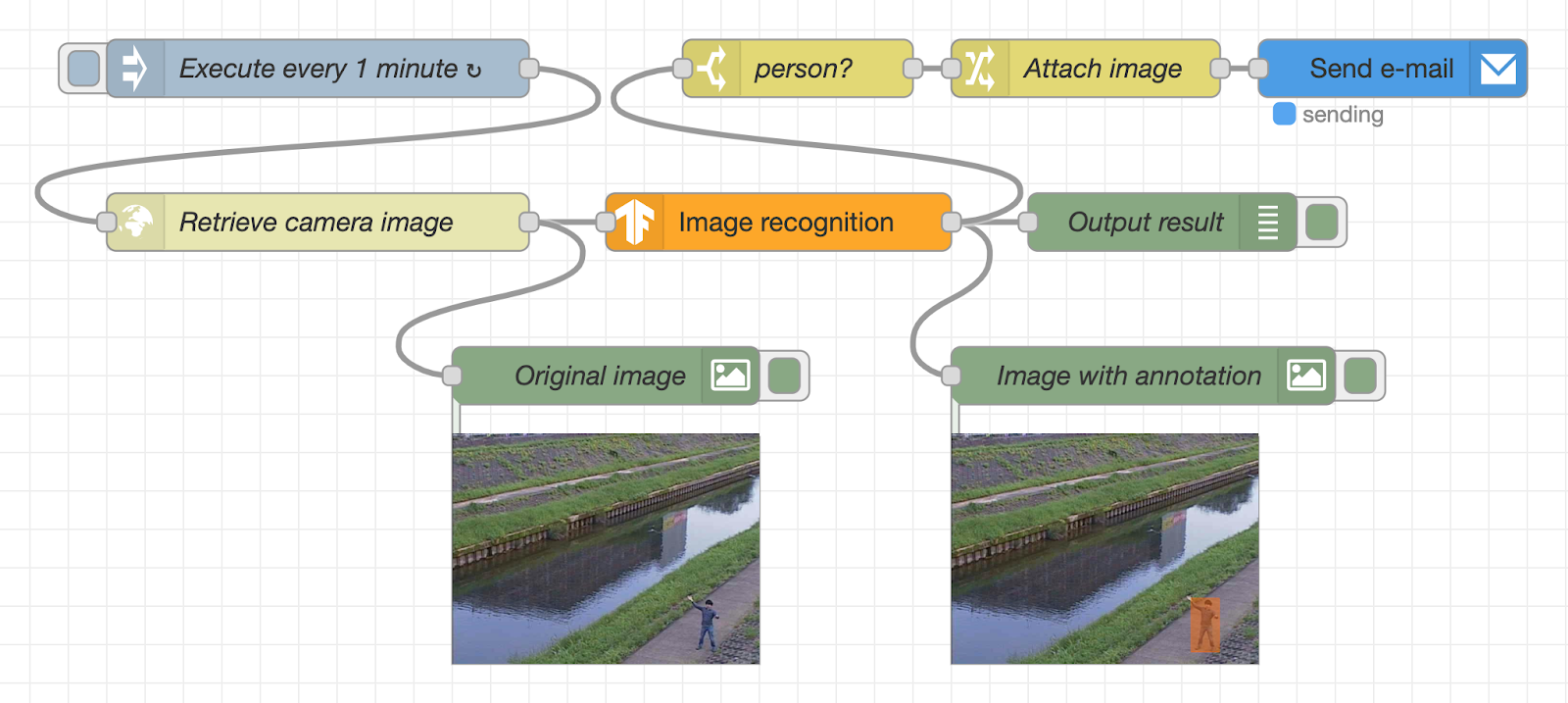
In a previous article, we introduced a procedure for developing an image recognition flow using Node-RED and TensorFlow.js. Now, let’s apply those learnings from what we have done and develop an e-mail alert system that uses a surveillance camera together with image recognition. As shown in the following image, we will create a flow that automatically sends an email alert when a suspicious person is captured within a surveillance camera frame.
Objective: Develop flow
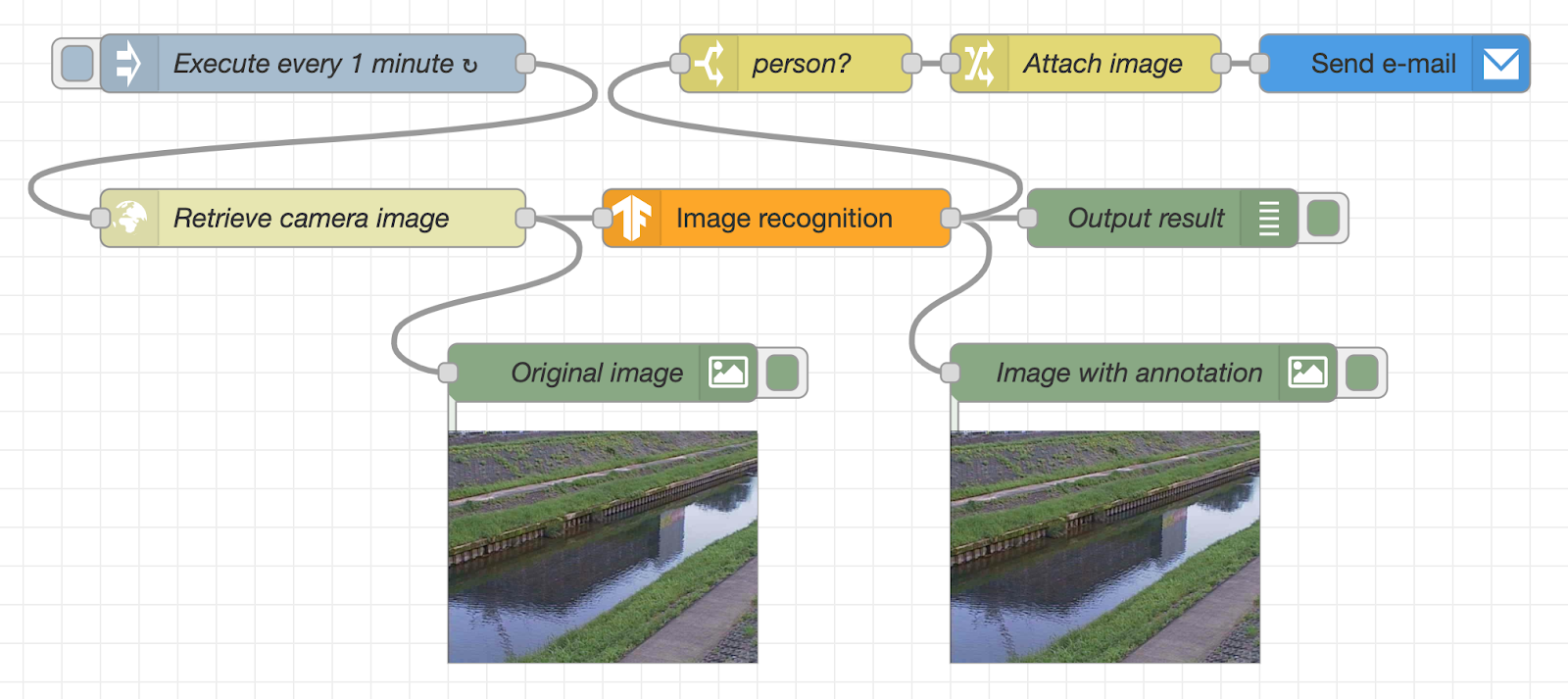
In this flow, the image of the surveillance camera is periodically acquired from the webserver, and the image is displayed under the “Original image” node in the lower left. After that, the image is recognized using the TensorFlow.js node. The recognition result and the image with recognition results are displayed under the debug tab and the “image with annotation” node, respectively.
If a person is detected by image recognition, an alert mail with the image file attached will be sent using the SendGrid node. Since it is difficult to set up a real surveillance camera, we will use a sample image sent by a surveillance camera in Kanagawa Prefecture of Japan to check the amount of water in the river.
We will explain the procedure for creating this flow in the following sections. For the Node-RED environment, use your local PC, a Raspberry Pi, or a cloud-based deployment.
Install the required nodes
Click the hamburger menu on the top right of the Node-RED flow editor, go to “Manage palette” -> “Palette” tab -> “Install” tab, and install the following nodes.
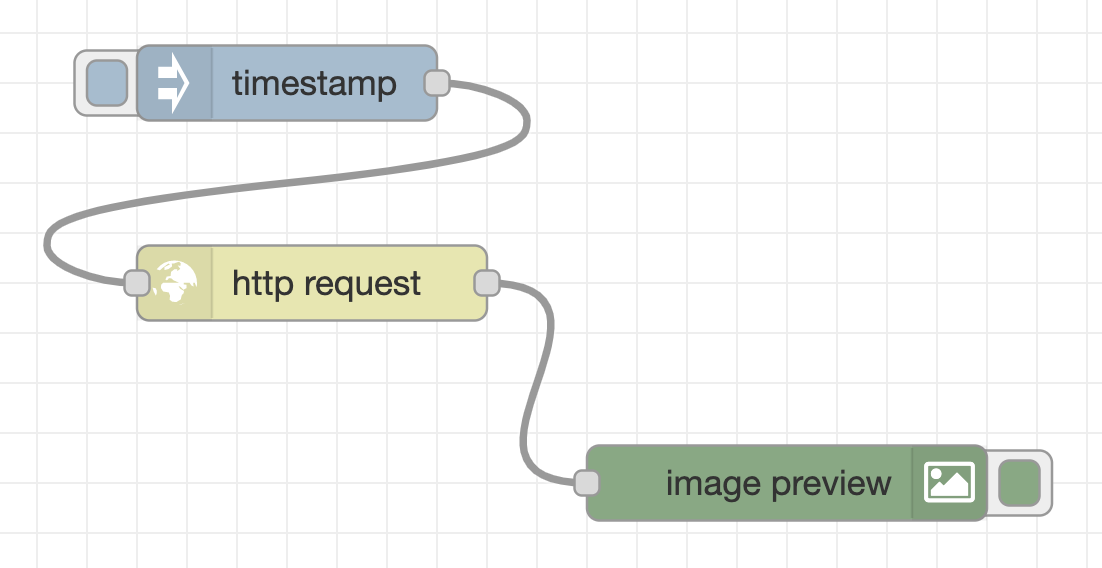
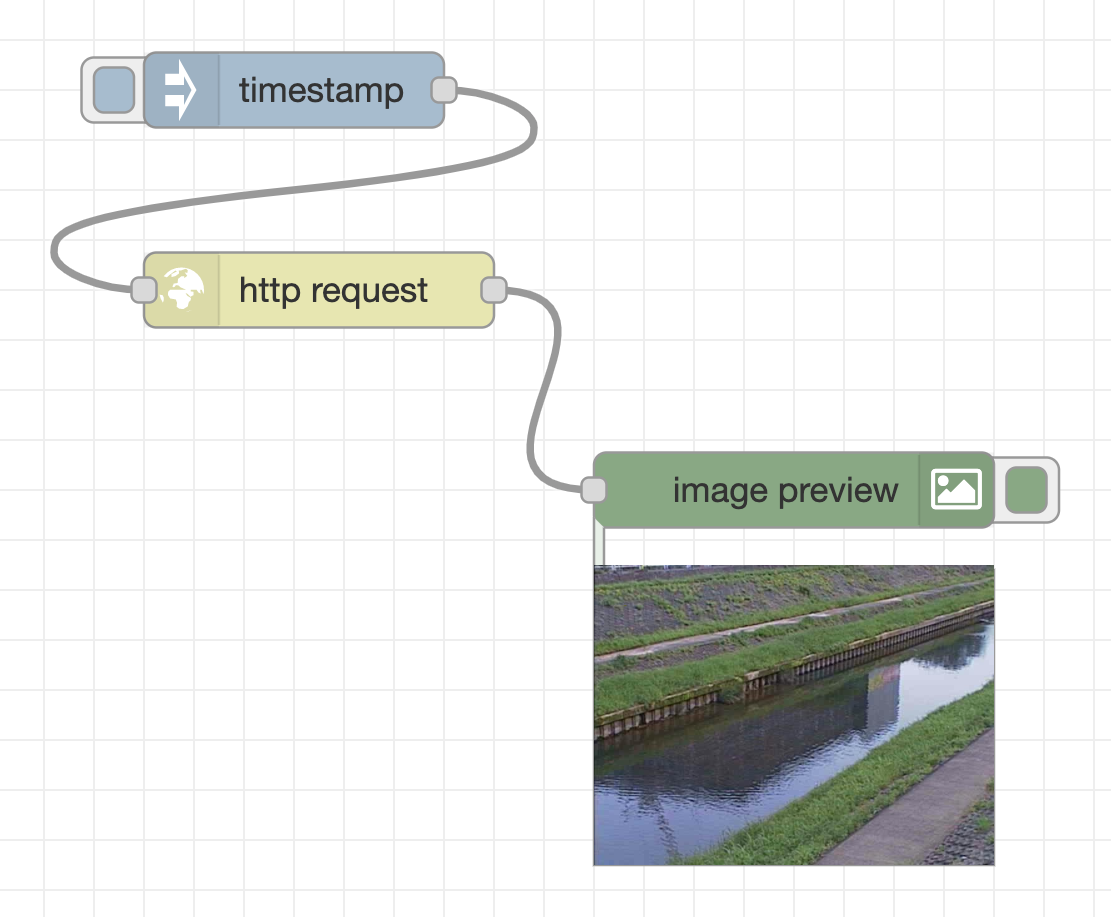
First, create a flow that acquires the image binary data from the webserver. As in the flow below, place an inject node (the name will be changed to “timestamp” when placed in the workspace), http request node, and image preview node, and connect them with wires in the user interface.
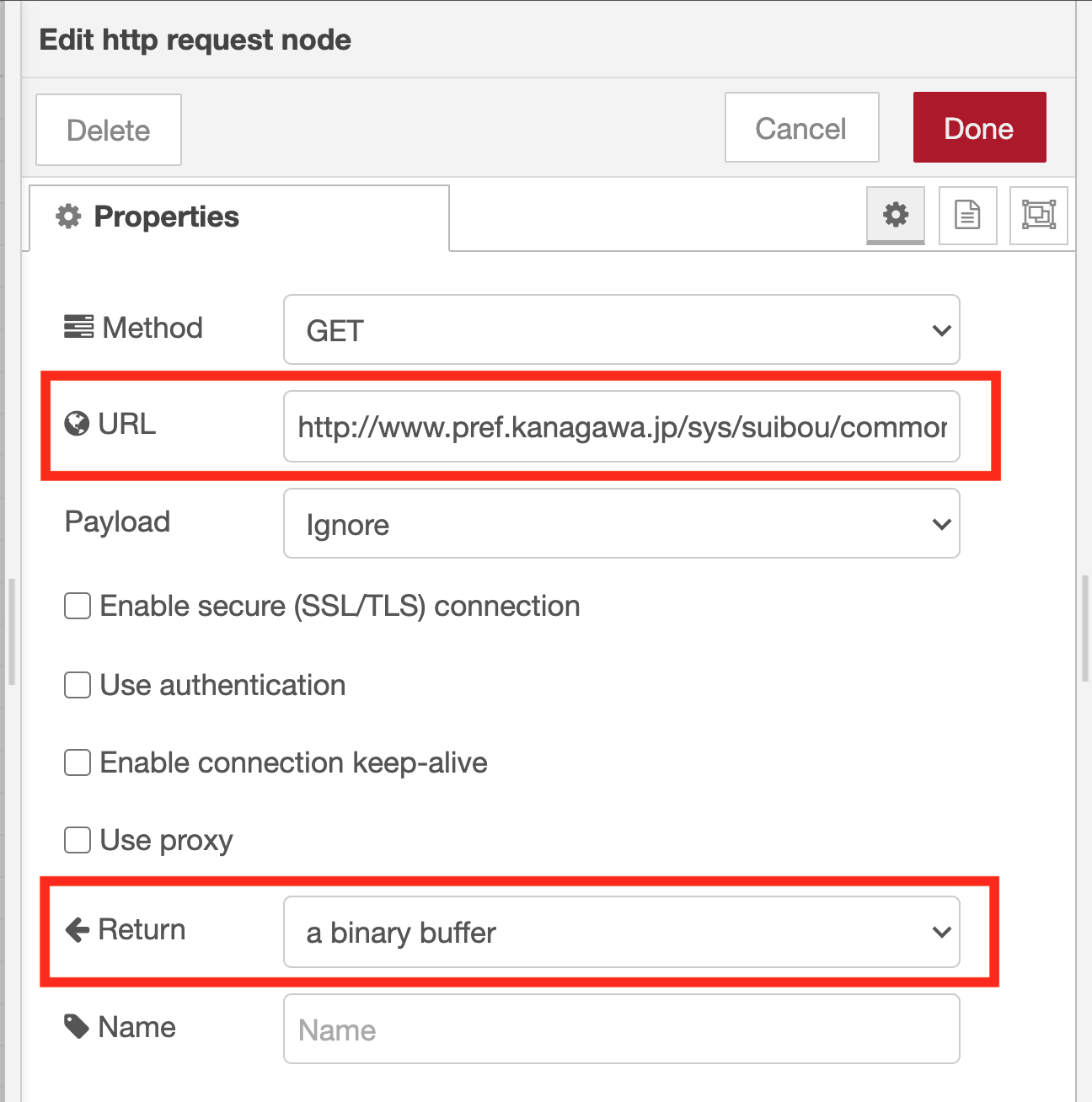
Then double-click the http request node to change the node property settings.
Adjust http request node property settings
Paste the URL of the surveillance camera image to the URL on the property setting screen of the http request node. (In Google Chrome, when you right-click on the image and select “Copy image address” from the menu, the URL of the image is copied to the clipboard.) Also, select “a binary buffer” as the output format.
Execute the flow to acquire image data
Click the Deploy button at the top right of the flow editor, then click the button to the inject node’s left. Then, the message is sent from the inject node to the http request node through the wire, and the image is acquired from the web server that provides the image of the surveillance camera. After receiving the image data, a message containing the data in binary format is sent to the image preview node, and the image is displayed under the image preview node.
An image of the river taken by the surveillance camera is displayed in the lower right.
Create a flow for image recognition of the acquired image data
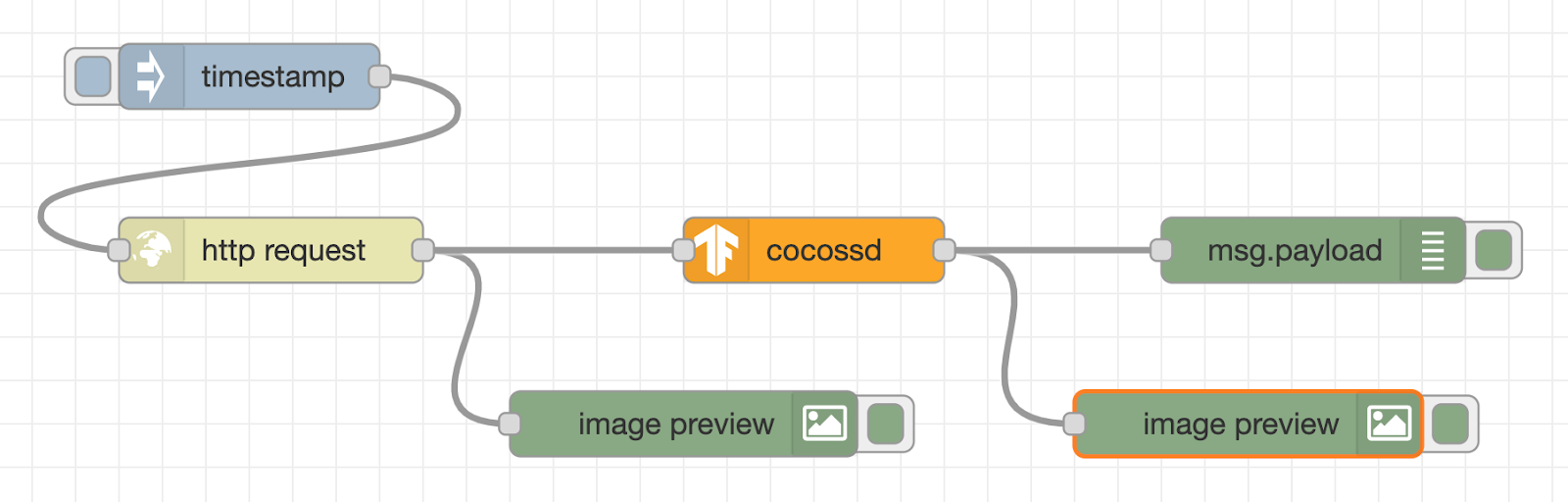
Next, create a flow that analyzes what is in the acquired image. Place a cocossd node, a debug node (the name will be changed to msg.payload when you place it), and a second image preview node.
Then, connect the output terminal on the right side of the http request node, and the input terminal on the left side of the cocossd node.
Next, connect the output terminal on the right side of the cocossd node and the debug node, the output terminal on the right side of the cocossd node, and the input terminal on the left side of the image preview node with the respective wires.
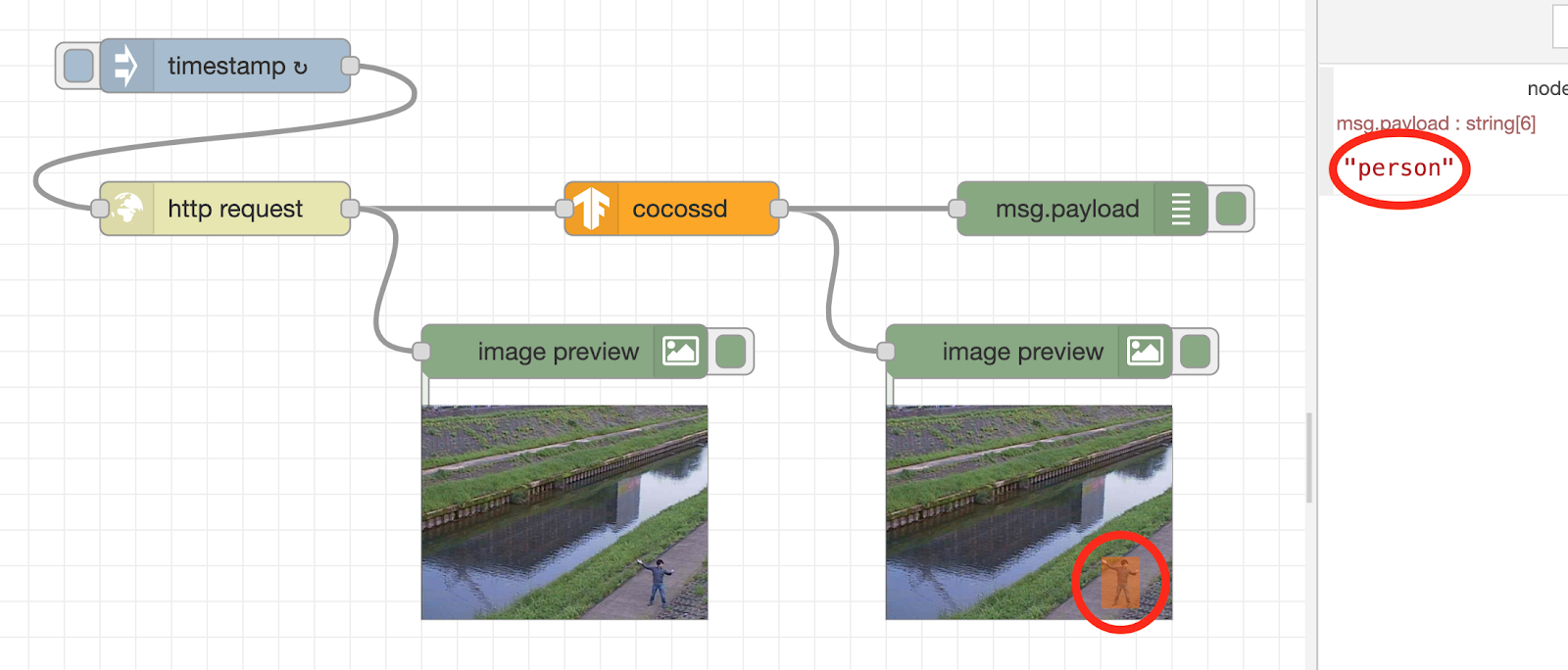
Through the wire, the binary data of the surveillance camera image is sent to the cocossd node, and after the image recognition is performed using TensorFlow.js, the object name is displayed in the debug node, and the image with the image recognition result is displayed in the image preview node.
The cocossd node is designed to store the object name in the variable msg.payload, and the binary data of the image with the annotation in the variable msg.annotatedInput.
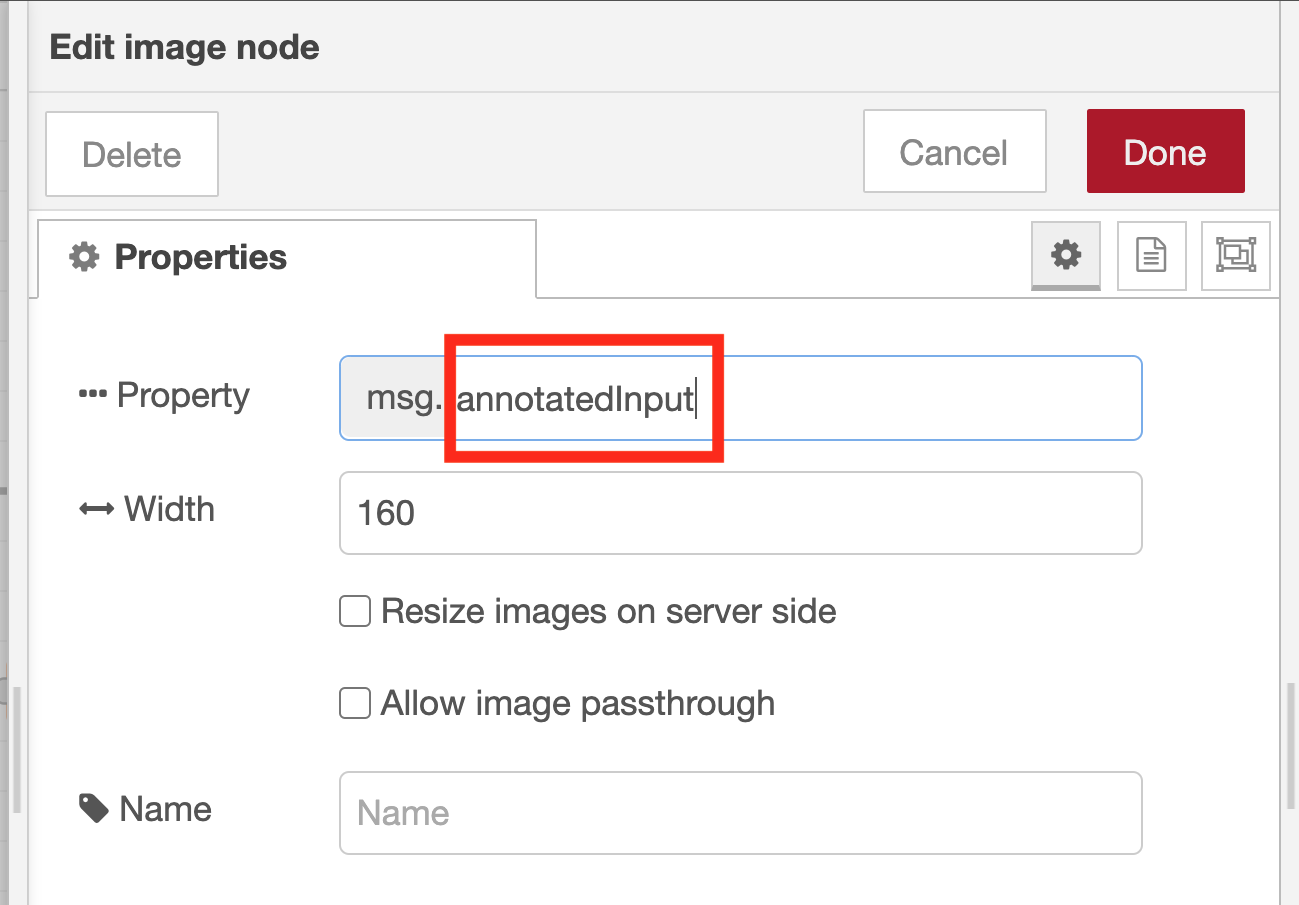
To make this flow work as intended, you need to double-click the image preview node used to display the image and change the node property settings.
Adjust image preview node property settings
By default, the image preview node displays the image data stored in the variable msg.payload. Here, change this default variable to msg.annotatedInput.
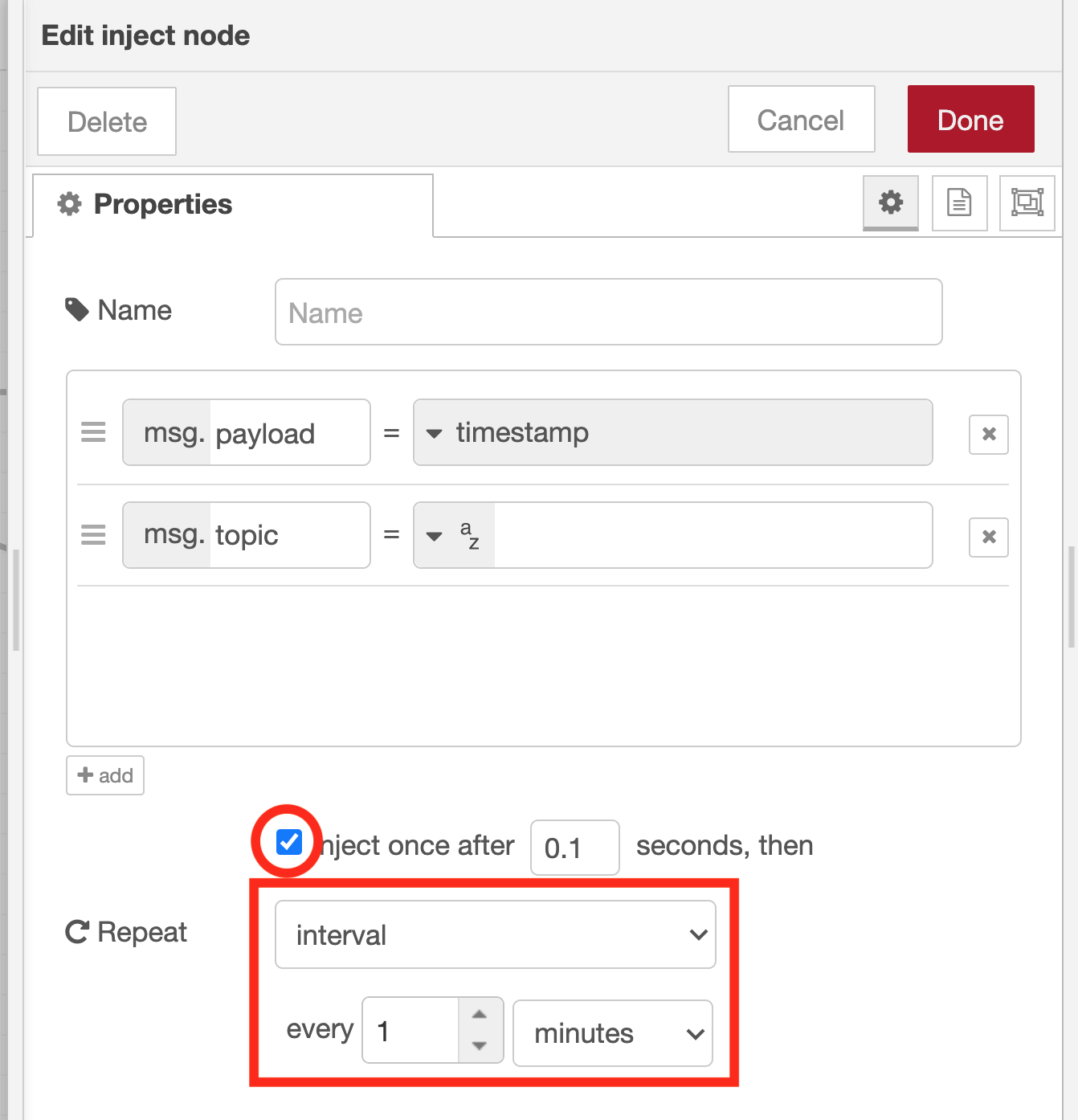
Adjust inject node property settings
Since the flow is run regularly every minute, the inject node’s property needs to be changed. In the Repeat pull-down menu, select “interval” and set “1 minute” as the time interval. Also, since we want to start the periodic run process immediately after pressing the Deploy button, select the checkbox on the left side of “inject once after 0.1 seconds”.
Run the flow for image recognition
The flow process will be run immediately after pressing the Deploy button. When the person (author) is shown on the surveillance camera, the image recognition result “person” is displayed in the debug tab on the right. Also, below the image preview node, you will see the image annotated with an orange square.
Create a flow of sending an email when a person caught in the surveillance camera
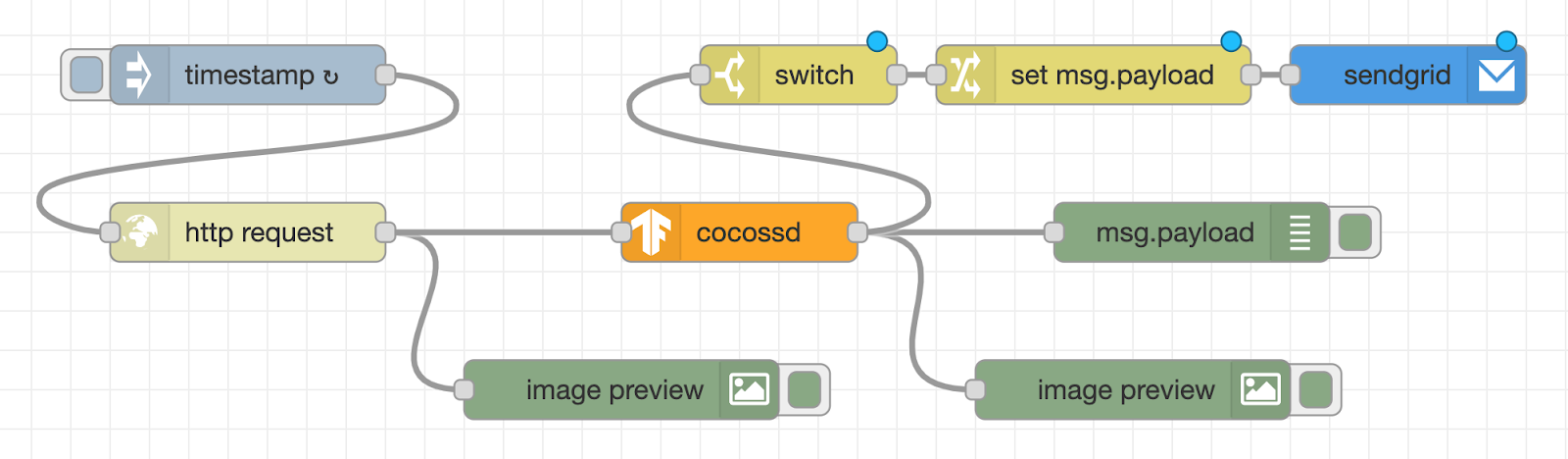
Finally, create a flow to send the annotated image by email when the object name in the image recognition result is “person”. As a subsequent node of the cocossd node, place a switch node that performs condition determination, a change node that assigns values, and a sendgrid node that sends an email, and connect each node with a wire.
Then, change the property settings for each node, as detailed in the sections below.
Adjust the switch node property settings
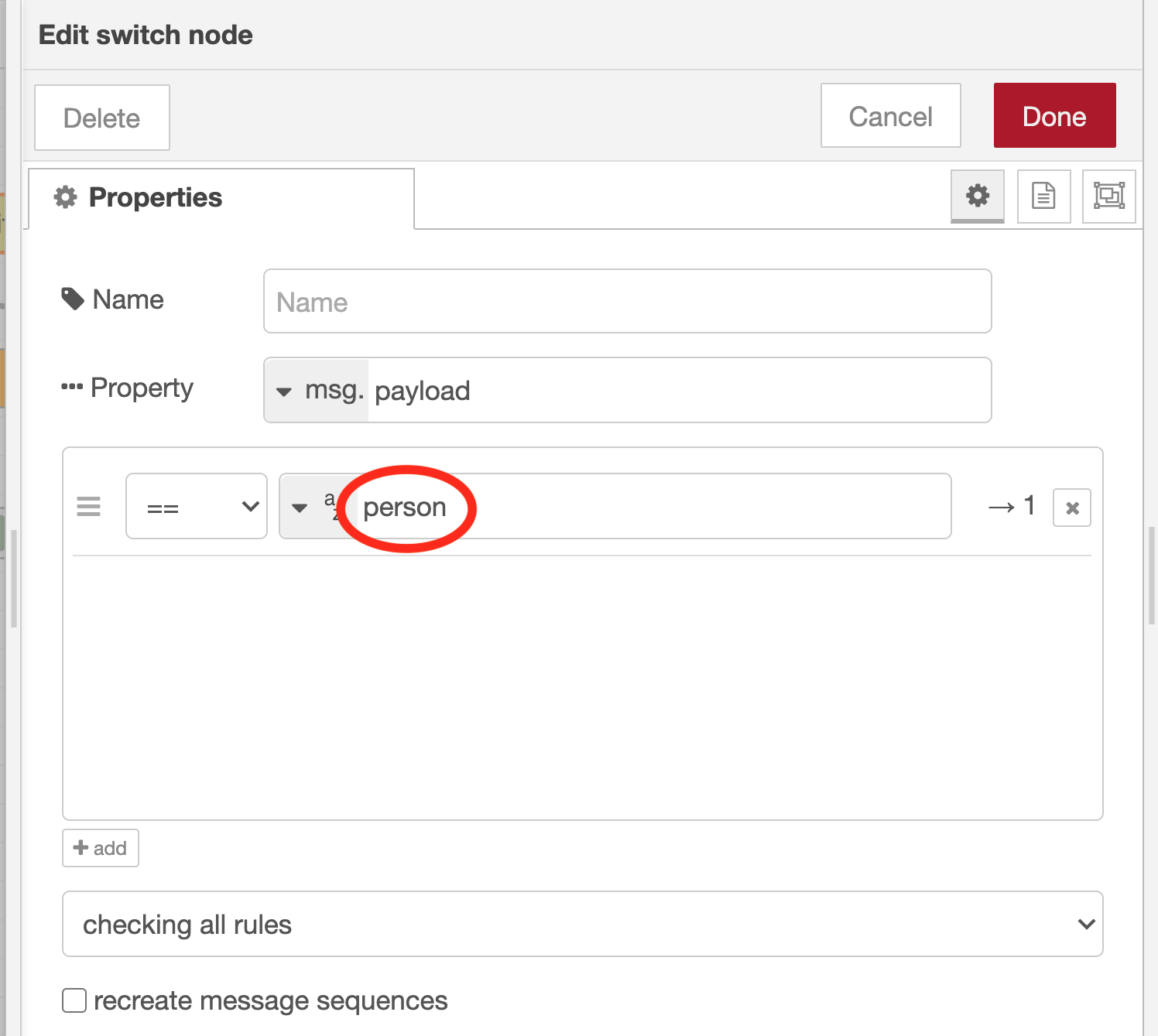
Set the rule to execute the subsequent flow only if msg.payload contains the string “person”
To set that rule, enter “person” in the comparison string for the condition “==” (on the right side of the “az” UX element in the property settings dialog for the switch node).
Adjust the change node property settings
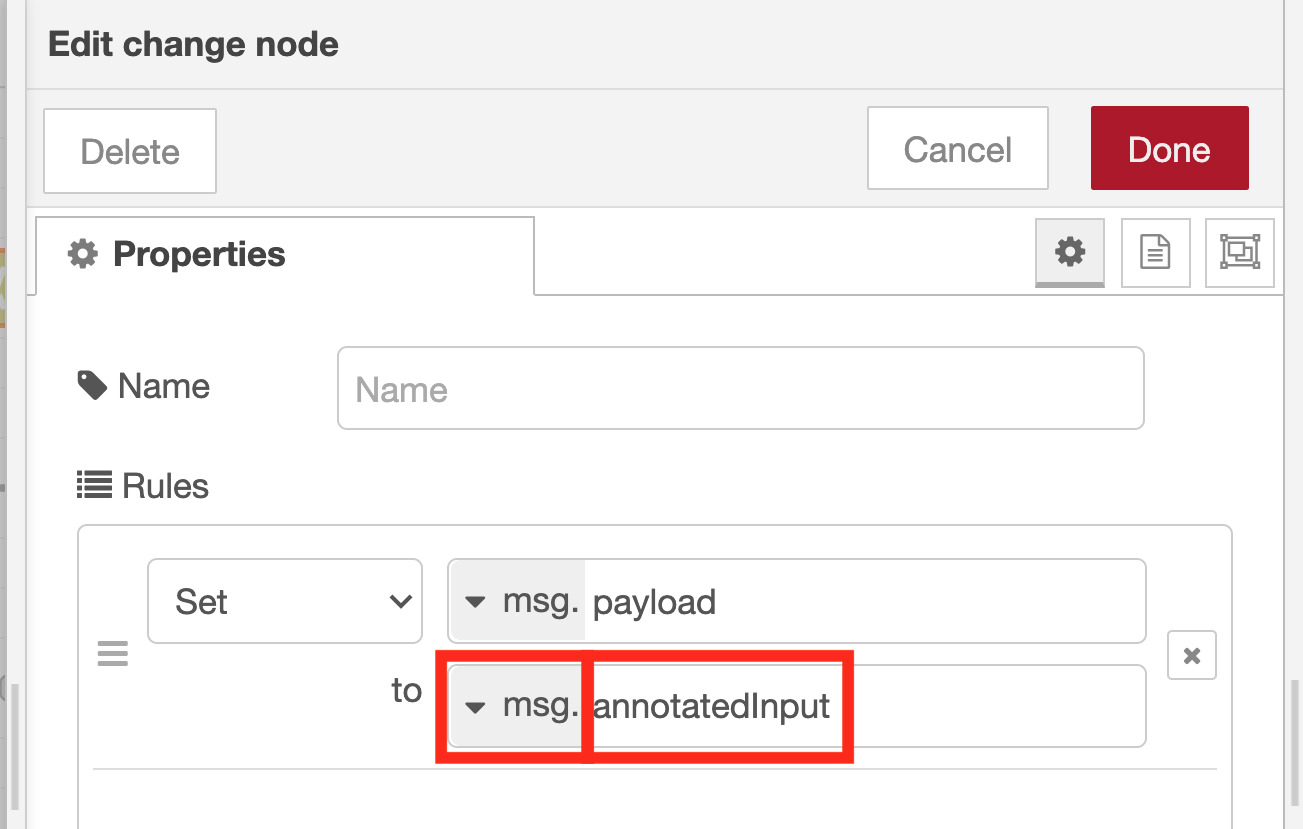
To attach the image with annotation to the email, substitute the image data stored in the variable msg.annotatedInput to the variable msg.payload. First, open the pull-down menu of “az” on the right side of the UX element of “Target value” and select “msg.”. Then enter “annotatedInput” in the text area on the right.
If you forget to change to “msg.” in the pull-down menu that appears when you click “az”, the flow often does not work well, so check again to be sure that it is set to “msg.”.
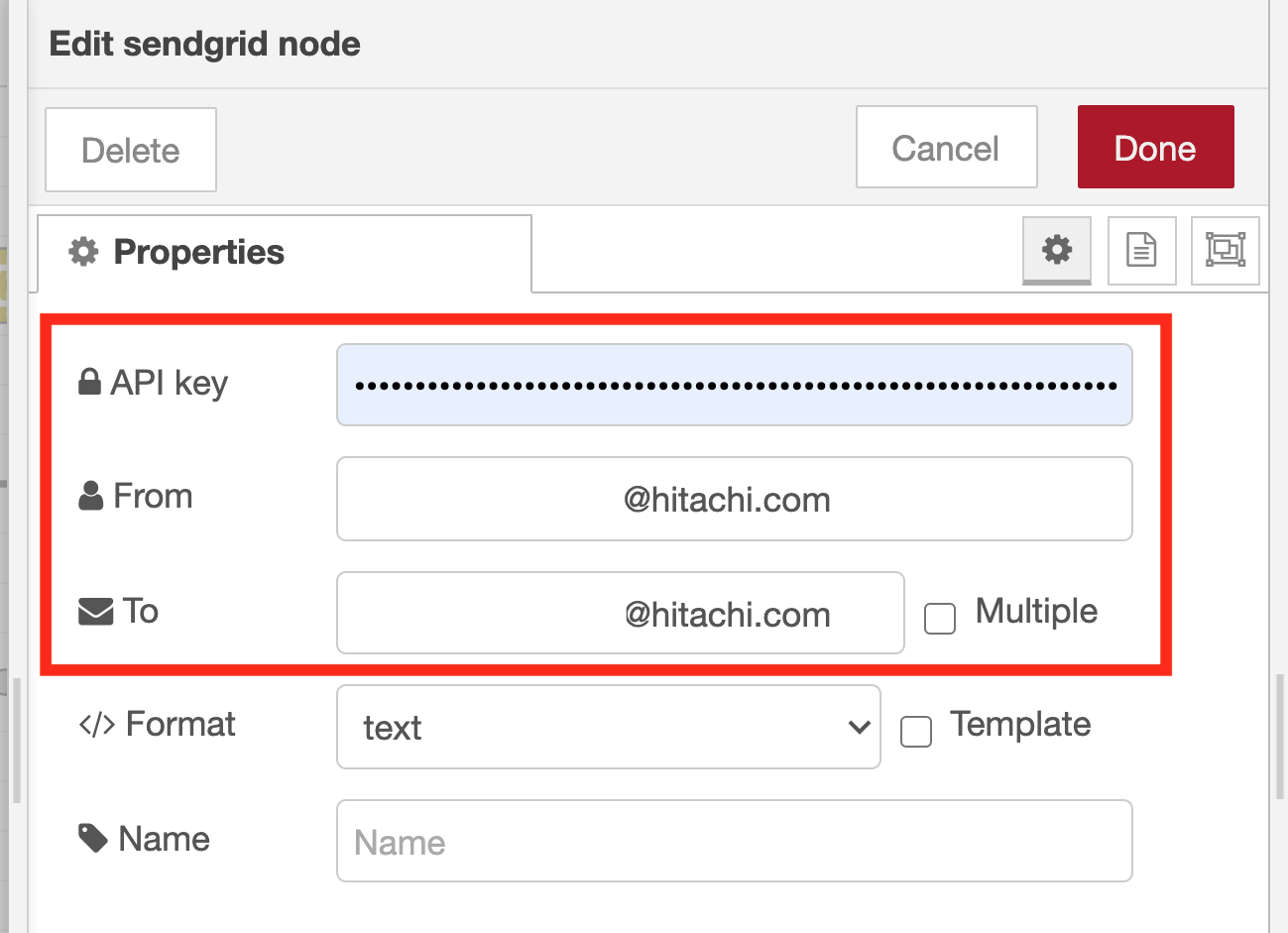
Adjust the sendgrid node property settings
Set the API key from the SendGrid management screen. And then input the sender email address and recipient email address.
Finally, to make it easier to see what each node is doing, open each node’s node properties, and set the appropriate name.
Validate the operation of the flow to send an email when the surveillance camera captures a person in frame
When a person is captured in the image of the surveillance camera, the image recognition result is displayed in the debug tab the same as in the previous flow of confirmation and the orange frame is displayed in the image under the image preview node of “Image with annotation”. You can see that the person is recognized correctly.
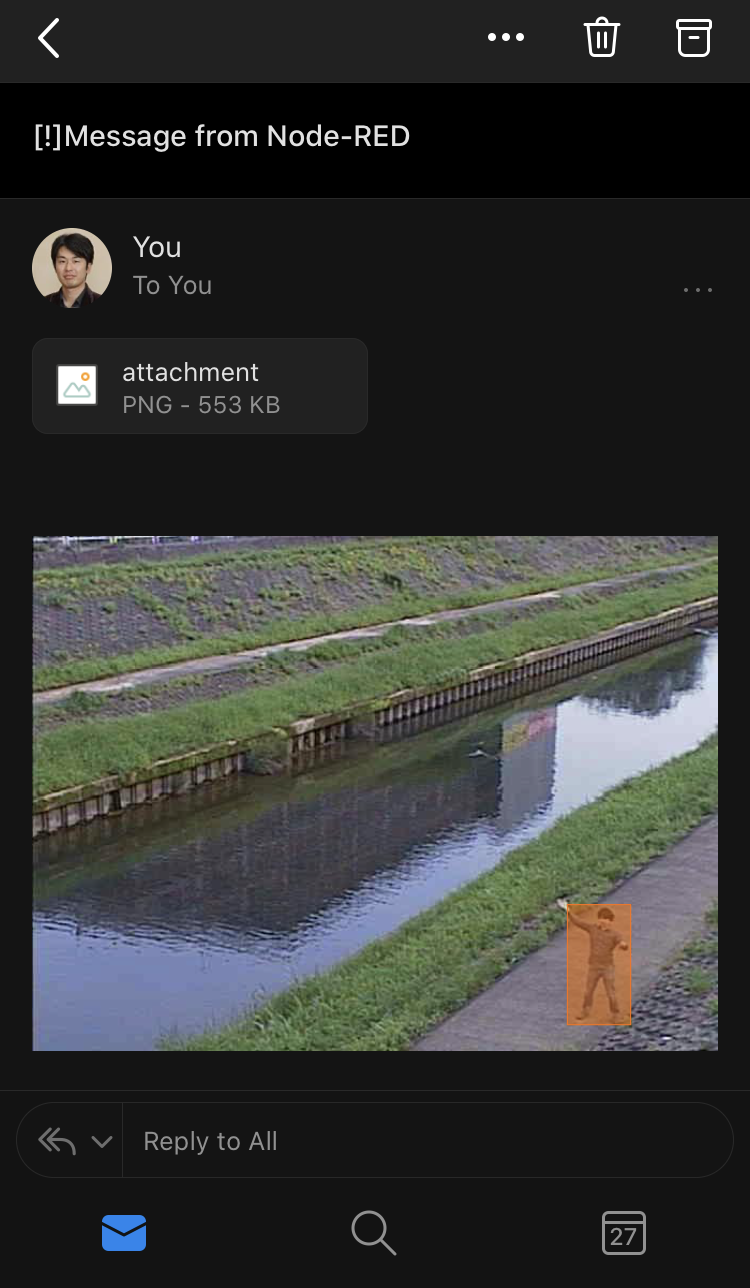
After that, if the judgment process, the substitution process, and the email transmission process works as designed, you will receive an email with the image file with the annotation attached to your smartphone as follows:
Conclusion
By using the flow created in this article, you can also build a simple security system for your own garden using a camera connected to a Raspberry Pi. At a larger scale, image recognition can also be run on image data acquired using network cameras that support protocols such as ONVIF.
About the author: Kazuhito Yokoi is an Engineer at Hitachi’s OSS Solution Center, located in Yokohama, Japan.
Earthquakes or the shaking doesn’t kill people, buildings do. If we can get people out of buildings in time, we can save lives. Grillo has founded OpenEEW in partnership with IBM and the Linux Foundation to allow anyone to build their own earthquake early-warning system. Swapnil Bhartiya, the founder of TFiR, talked to the founder of Grillo on behalf of The Linux Foundation to learn more about the project.
Here is the transcript of the interview:
Swapnil Bhartiya: If you look at these natural phenomena like earthquakes, there’s no way to fight with nature. We have to learn to coexist with them. Early warnings are the best thing to do. And we have all these technologies – IoTs and AI/ML. All those things are there, but we still don’t know much about these phenomena. So, what I do want to understand is if you look at an earthquake, we’ll see that in some countries the damage is much more than some other places. What is the reason for that?
Andres Meira: earthquakes disproportionately affect countries that don’t have great construction. And so, if you look at places like Mexico, the Caribbean, much of Latin America, Nepal, even some parts of India in the North and the Himalayas, you find that earthquakes can cause more damage than say in California or in Tokyo. The reason is it is buildings that ultimately kill people, not the shaking itself. So, if you can find a way to get people out of buildings before the shaking that’s really the solution here. There are many things that we don’t know about earthquakes. It’s obviously a whole field of study, but we can’t tell you for example, that an earthquake can happen in 10 years or five years. We can give you some probabilities, but not enough for you to act on.
What we can say is that an earthquake is happening right now. These technologies are all about reducing the latency so that when we know an earthquake is happening in milliseconds we can be telling people who will be affected by that event.
Swapnil Bhartiya: What kind of work is going on to better understand earthquakes themselves?
Andres Meira: I have a very narrow focus. I’m not a seismologist and I have a very narrow focus related to detecting earthquakes and alerting people. I think in the world of seismology, there are a lot of efforts to understand the tectonic movement, but I would say there are a few interesting things happening that I know of. For example, undersea cables. People in Chile and other places are looking at undersea telecommunications cables and the effects that any sort of seismic movement have on the signals. They can actually use that as a detection system. But when you talk about some of the really deep earthquakes, 60-100 miles beneath the surface, man has not yet created holes deep enough for us to place sensors. So we’re very limited as to actually detecting earthquakes at a great depth. We have to wait for them to affect us near the surface.
Swapnil Bhartiya: So then how do these earthquake early warning systems work? I want to understand from a couple of points: What does the device itself look like? What do those sensors look like? What does the software look like? And how do you kind of share data and interact with each other?
Andres Meira: The sensors that we use, we’ve developed several iterations over the last couple of years and effectively, they are a small microcontroller, an accelerometer, this is the core component and some other components. What the device does is it records accelerations. So, it looks on the X, Y, and Z axes and just records accelerations from the ground so we are very fussy about how we install our sensors. Anybody can install it in their home through this OpenEEW initiative that we’re doing.
The sensors themselves record shaking accelerations and we send all of those accelerations in quite large messages using MQTT. We send them every second from every sensor and all of this data is collected in the cloud, and in real-time we run algorithms. We want to know that the shaking, which the accelerometer is getting is not a passing truck. It’s actually an earthquake.
So we’ve developed the algorithms that can tell those things apart. And of course, we wait for one or two sensors to confirm the same event so that we don’t get any false positives because you can still get some errors. Once we have that confirmation in the cloud we can send a message to all of the client devices. If you have an app, you will be receiving a message saying, there’s an earthquake at this location, and your device will then be calculating how long it will take to reach it. Therefore, how much energy will be lost and therefore, what shaking you’re going to be expecting very soon.
Swapnil Bhartiya: Where are these devices installed?
Andres Meira: They are installed at the moment in several countries – Mexico, Chile, Costa Rica, and Puerto Rico. We are very fussy about how people install them, and in fact, on the OpenEEW website, we have a guide for this. We really require that they’re installed on the ground floor because the higher up you go, the different the frequencies of the building movement, which affects the recordings. We need it to be fixed to a solid structural element. So this could be a column or a reinforced wall, something which is rigid and it needs to be away from the noise. So it wouldn’t be great if it’s near a door that was constantly opening and closing. Although we can handle that to some extent. As long as you are within the parameters, and ideally we look for good internet connections, although we have cellular versions as well, then that’s all we need.
The real name of the game here is a quantity more than quality. If you can have a lot of sensors, it doesn’t matter if one is out. It doesn’t matter if the quality is down because we’re waiting for confirmation from other ones and redundancy is how you achieve a stable network.
Swapnil Bhartiya: What is the latency between the time when sensors detect an earthquake and the warning is sent out? Does it also mean that the further you are from the epicenter, the more time you will get to leave a building?
Andres Meira: So the time that a user gaps in terms of what we call the window of opportunity for them to actually act on the information is a variable and it depends on where the earthquake is relative to the user. So, I’ll give you an example. Right now, I’m in Mexico City. If we are detecting an earthquake in Acapulco, then you might get 60 seconds of advanced warning because an earthquake travels at more or less a fixed velocity, which is unknown and so the distance and the velocity gives you the time that you’re going to be getting.
If that earthquake was in the South of Mexico in Oaxaca, we might get two minutes. Now, this is a variable. So of course, if you are in Istanbul, you might be very near the fault line or Kathmandu. You might be near the fault line. If the distance is less than what I just described, the time goes down. But even if you only have five seconds or 10 seconds, which might happen in the Bay area, for example, that’s still okay. You can still ask children in a school to get underneath the furniture. You can still ask surgeons in a hospital to stop doing the surgery. There’s many things you can do and there are also automated things. You can shut off elevators or turn off gas pipes. So anytime is good, but the actual time itself is a variable.
Swapnil Bhartiya: The most interesting thing that you are doing is that you are also open sourcing some of these technologies. Talk about what components you have open source and why.
Andres Meira: Open sourcing was a tough decision for us. It wasn’t something we felt comfortable with initially because we spent several years developing these tools, and we’re obviously very proud. I think that there came a point where we realized why are we doing this? Are we doing this to develop cool technologies to make some money or to save lives? All of us live in Mexico, all of us have seen the devastation of these things. We realized that open source was the only way to really accelerate what we’re doing.
If we want to reach people in these countries that I’ve mentioned; if we really want people to work on our technology as well and make it better, which means better alert times, less false positives. If we want to really take this to the next level, then we can’t do it on our own. It will take a long time and we may never get there.
So that was the idea for the open source. And then we thought about what we could do with open source. We identified three of our core technologies and by that I mean the sensors, the detection system, which lives in the cloud, but could also live on a Raspberry Pi, and then the way we alert people. The last part is really quite open. It depends on the context. It could be a radio station. It could be a mobile app, which we’ve got on the website, on the GitHub. It could be many things. Loudspeakers. So those three core components, we now have published in our repo, which is OpenEEW on GitHub. And from there, people can pick and choose.
It might be that some people are data scientists so they might go just for the data because we also publish over a terabyte of accelerometer data from our networks. So people might be developing new detection systems using machine learning, and we’ve got instructions for that and we would very much welcome it. Then we have something for the people who do front end development. So they might be helping us with the applications and then we also have people something for the makers and the hardware guys. So they might be interested in working on the census and the firmware. There’s really a whole suite of technologies that we published.
Swapnil Bhartiya: There are other earthquake warning systems. How is OpenEEW different?
Andres Meira: I would divide the other systems into two categories. I would look at the national systems. I would look at say the Japanese or the California and the West coast system called Shake Alert. Those are systems with significant public funding and have taken decades to develop. I would put those into one category and another category I would look at some applications that people have developed. My Shake or Skylert, or there’s many of them.
If you look at the first category, I would say that the main difference is that we understand the limitations of those systems because an earthquake in Northern Mexico is going to affect California and vice versa. An earthquake in Guatemala is going to affect Mexico and vice versa. An earthquake in Dominican Republic is going to affect Puerto Rico. The point is that earthquakes don’t respect geography or political boundaries. And so we think national systems are limited, and so far they are limited by their borders. So, that was the first thing.
In terms of the technology, actually in many ways, the MEMS accelerometers that we use now are streets ahead of where we were a couple of years ago. And it really allows us to detect earthquakes hundreds of kilometers away. And actually, we can perform as well as these national systems. We’ve studied our system versus the Mexican national system called SASMEX, and more often than not, we are faster and more accurate. It’s on our website. So there’s no reason to say that our technology is worse. In fact, having cheaper sensors means you can have huge networks and these arrays are what make all the difference.
In terms of the private ones, the problems with those are that sometimes they don’t have the investment to really do wide coverage. So the open sources are our strength there because we can rely on many people to add to the project.
Swapnil Bhartiya: What kind of roadmap do you have for the project? How do you see the evolution of the project itself?
Andres Meira: So this has been a new area for me; I’ve had to learn. The governance of OpenEEW as of today, like you mentioned, is now under the umbrella of the Linux Foundation. So this is now a Linux Foundation project and they have certain prerequisites. So we had to form a technical committee. This committee makes the steering decisions and creates the roadmap you mentioned. So, the roadmap is now published on the GitHub, and it’s a work in progress, but effectively we’re looking 12 months ahead and we’ve identified some areas that really need priority. Machine learning, as you mentioned, is definitely something that will be a huge change in this world because if we can detect earthquakes, potentially with just a single station with a much higher degree of certainty, then we can create networks that are less dense. So you can have something in Northern India and in Nepal, in Ecuador, with just a handful of sensors. So that’s a real Holy grail for us.
We also are asking on the roadmap for people to work with us in lots of other areas. In terms of the sensors themselves, we want to do more detection on the edge. We feel that edge computing with the sensors is obviously a much better solution than what we do now, which has a lot of cloud detection. But if we can move a lot of that work to the actual devices, then I think we’re going to have much smarter networks and less telemetry, which opens up new connectivity options. So, the sensors as well are another area of priority on the road map.
Swapnil Bhartiya: What kind of people would you like to get involved with and how can they get involved?
Andres Meira: So as of today, we’re formally announcing the initiative and I would really invite people to go to OpenEEW.com, where we’ve got a site that outlines some areas that people can get involved with. We’ve tried to consider what type of people would join the project. So you’re going to get seismologists. We have seismologists from Harvard University and from other areas. They’re most interested in the data from what we’ve seen so far. They’re going to be looking at the data sets that we’ve offered and some of them are already looking at machine learning. So there’s many things that they might be looking at. Of course, anyone involved with Python and machine learning, data scientists in general, might also do similar things. Ultimately, you can be agnostic about seismology. It shouldn’t put you off because we’ve tried to abstract it away. We’ve got down to the point where this is really just data.
Then we’ve also identified the engineers and the makers, and we’ve tried to guide them towards the repos, like the sensory posts. We are asking them to help us with the firmware and the hardware. And then we’ve got for your more typical full stack or front end developer, we’ve got some other repos that deal with the actual applications. How does the user get the data? How does the user get the alerts? There’s a lot of work we can be doing there as well.
So, different people might have different interests. Someone might just want to take it all. Maybe someone might want to start a network in the community, but isn’t technical and that’s fine. We have a Slack channel where people can join and people can say, “Hey, I’m in this part of the world and I’m looking for people to help me with the sensors. I can do this part.” Maybe an entrepreneur might want to join and look for the technical people.
So, we’re just open to anybody who is keen on the mission, and they’re welcome to join.
Zephyr is gaining momentum where more and more companies are embracing this open source project for their embedded devices. However, security is becoming a huge concern for these connected devices. The NCC Group recently conducted an evaluation and security assessment of the project to help harden it against attacks. In the interview, Kate Stewart, Senior Director of Strategic Programs at Linux Foundation talk about the assessment and the evolution of the project.
Here is a quick transcript of the interview:
Swapnil Bhartiya: The NCC group recently evaluated Linux for security. Can you talk about what was the outcome of that evaluation?
Kate Stewart: We’re very thankful for the NCC group for the work that they did and helping us to get Zephyr hardened further. In some senses when it had first hit us, it was like, “Okay, they’re taking us seriously now. Awesome.” And the reason they’re doing this is that their customers are asking for it. They’ve got people who are very interested in Zephyr so they decided to invest the time doing the research to see what they could find. And the fact that we’re good enough to critique now is a nice positive for the project, no question.
Up till this point, we’d had been getting some vulnerabilities that researchers had noticed in certain areas and had to tell us about. We’d issued CVEs so we had a process down, but suddenly being hit with the whole bulk of those like that was like, “Okay, time to up our game guys.” And so, what we’ve done is we found out we didn’t have a good way of letting people who have products with Zephyr based on them know about our vulnerabilities. And what we wanted to be able to do is make it clear that if people have products and they have them out in the market and that they want to know if there’s a vulnerability. We just added a new webpage so they know how to register, and they can let us know to contact them.
The challenge of embedded is you don’t quite know where the software is. We’ve got a lot of people downloading Zephyr, we got a lot of people using Zephyr. We’re seeing people upstreaming things all the time, but we don’t know where the products are, it’s all word of mouth to a large extent. There’re no tracers or anything else, you don’t want to do that in an embedded space on IoT; battery life is important. And so, it’s pretty key for figuring out how do we let people who want to be notified know.
We’d registered as a CNA with Mitre several years ago now and we can assign CVE numbers in the project. But what we didn’t have was a good way of reaching out to people beyond our membership under embargo so that we can give them time to remediate any issues that we’re fixing. By changing our policies, it’s gone from a 60-day embargo window to a 90-day embargo window. In the first 30 days, we’re working internally to get the team to fix the issues and then we’ve got a 60-day window for our people who do products to basically remediate in the field if necessary. So, getting ourselves useful for product makers was one of the big focuses this year.
Swapnil Bhartiya: Since Zephyr’s LTS release was made last year, can you talk about the new releases, especially from the security perspective because I think the latest version is 2.3.0?
Kate Stewart: Yeah, 2.3.0 and then we also have 1.14.2. and 1.14 is our LTS-1 as we say. And we’ve put an update out to it with the security fixes and a long-term stable like the Linux kernel has security fixes and bug fixes backported into it so that people can build products on it and keep it active over time without as much change in the interfaces and everything else that we’re doing in the mainline development tree and what we’ve just done with the 2.3.
2.3 has a lot of new features in it and we’ve got all these vulnerabilities remediated. There’s a lot more coming up down the road, so the community right now is working. We’ve adopted new set of coding guidelines for the project and we will be working on that so we can get ourselves ready for going after safety certifications next year. So there’s a lot of code in motion right now, but there’s a lot of new features being added every day. It’s great.
Swapnil Bhartiya: I also want to talk a bit about the community side of it. Can you talk about how the community is growing new use cases?
Kate Stewart: We’ve just added two new members into Zephyr. We’ve got Teenage Engineering has just joined us and Laird Connectivity has just joined us and it’s really cool to start seeing these products coming out. There are some rather interesting technologies and products that are showing up and so I’m really looking forward to being able to have blog posts about them.
Laird Connectivity is basically a small device running Zephyr that you can use for monitoring distance without recording other information. So, in days of COVID, we need to start figuring out technology assists to help us keep the risk down. Laird Connectivity has devices for that.
So we’re seeing a lot of innovation happening very quickly in Zephyr and that’s really Zephyr’s strength is it’s got a very solid code base and lets people add their innovation on top.
Swapnil Bhartiya: What role do you think Zephyr going to play in the post-COVID-19 world?
Kate Stewart: Well, I think they offer us interesting opportunities. Some of the technologies that are being looked at for monitoring for instance – we have distance monitoring, contact tracing and things like that. We can either do it very manually or we can start to take advantage of the technology infrastructures to do so. But people may not want to have a device effectively monitoring them all the time. They may just want to know exactly, position-wise, where they are. So that’s potentially some degree of control over what’s being sent into the tracing and tracking.
These sorts of technologies I think will be helping us improve things over time. I think there’s a lot of knowledge that we’re getting out of these and ways we can optimize the information and the RTOS and the sensors are discrete functionality and are improving how do we look at things.
Swapnil Bhartiya: There are so many people who are using Zephyr but since it is open source we not even aware of them. How do you ensure that whether someone is an official member of the project or not if they are running Zephyr their devices are secure?
Kate Stewart: We do a lot of testing with Zephyr, there’s a tremendous amount of test infrastructure. There’s the whole regression infrastructure. We work to various thresholds of quality levels and we’ve got a lot of expertise and have publicly documented all of our best practices. A security team is a top-notch group of people. I’m really so proud to be able to work with them. They do a really good job of caring about the issues as well as finding them, debugging them and making sure anything that comes up gets solved. So in that sense, there’s a lot of really great people working on Zephyr and it makes it a really fun community to work with, no question. In fact, it’s growing fast actually.
Swapnil Bhartiya: Kate, thank you so much for taking your time out and talking to me today about these projects.
In 2017, Mohamed Al Samman was working on the Linux kernel, doing analysis, debugging, and compiling. He had also built an open source Linux firewall, and a kernel module to monitor power supply electrical current status (AC/DC) by using the Linux kernel notifier. He hoped to become a full-time kernel developer, and expand the kernel community in Egypt, which led him to apply for, and be awarded, a Linux Foundation Training (LiFT) Scholarship in the Linux Kernel Guru category.
We followed up with Mohamed recently to hear what he’s been up to since completing his Linux Foundation training.
Over the last few decades, we’ve seen Linux steadily grow and become the most widely used operating system kernel. From sensors to supercomputers, we see it used in spacecraft, automobiles, smartphones, watches, and many more devices in our everyday lives. Since the Linux Foundation started publishing the Linux Kernel Development Reports in 2008, we’ve observed progress between points in time.
Since that original 1991 release, Linux has become one of the most successful collaborations in history, with over 20,000 contributors. Given the recent announcement of version 5.8 as one of the largest yet, there’s no sign of it slowing down, with the latest release showing a new record of over ten commits per hour.
In this report, we look at Linux’s entire history. Our analysis of Linux is based on early releases, and the developer community commits from BitKeeper and git since the first Kernel release on September 17, 1991, through August 2, 2020. With the 5.8 release tagging on August 2, 2020, and with the merge window for 5.9 now complete, over a million commits of recorded Linux Kernel history are available to analyze from the last 29 years.
This report looks back through the history of the Linux kernel and the impact of some of the best practices and tooling infrastructure that has emerged to enable one of the most significant software collaborations known.