

One of the most popular tasks undertaken on Linux is development. With good reason: Businesses rely on Linux. Without Linux, technology simply wouldn’t meet the demands of today’s ever-evolving world. Because of that, developers are constantly working to improve the environments with which they work. One way to manage such improvements is to have the right platform to start with. Thankfully, this is Linux, so you always have a plethora of choices.
But sometimes, too many choices can be a problem in and of itself. Which distribution is right for your development needs? That, of course, depends on what you’re developing, but certain distributions that just make sense to use as a foundation for your task. I’ll highlight five distributions I consider the best for developers in 2019.
Ubuntu
Let’s not mince words here. Although the Linux Mint faithful are an incredibly loyal group (with good reason, their distro of choice is fantastic), Ubuntu Linux gets the nod here. Why? Because, thanks to the likes of AWS, Ubuntu is one of the most deployed server operating systems. That means developing on a Ubuntu desktop distribution makes for a much easier translation to Ubuntu Server. And because Ubuntu makes it incredibly easy to develop for, work with, and deploy containers, it makes perfect sense that you’d want to work with this platform. Couple that with Ubuntu’s inclusion of Snap Packages, and Canonical’s operating system gets yet another boost in popularity.
But it’s not just about what you can do with Ubuntu, it’s how easily you can do it. For nearly every task, Ubuntu is an incredibly easy distribution to use. And because Ubuntu is so popular, chances are every tool and IDE you want to work with can be easily installed from the Ubuntu Software GUI (Figure 1).

If you’re looking for ease of use, simplicity of migration, and plenty of available tools, you cannot go wrong with Ubuntu as a development platform.
openSUSE
There’s a very specific reason why I add openSUSE to this list. Not only is it an outstanding desktop distribution, it’s also one of the best rolling releases you’ll find on the market. So if you’re wanting to develop with and release for the most recent software available, openSUSE Tumbleweed should be one of your top choices. If you want to leverage the latest releases of your favorite IDEs, if you always want to make sure you’re developing with the most recent libraries and toolkits, Tumbleweed is your platform.
But openSUSE doesn’t just offer a rolling release distribution. If you’d rather make use of a standard release platform, openSUSE Leap is what you want.
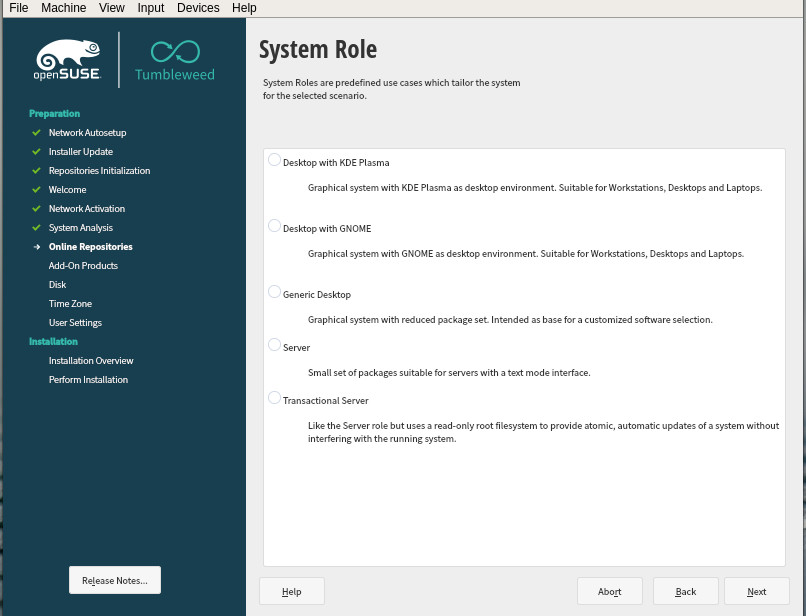
Of course, it’s not just about standard or rolling releases. The openSUSE platform also has a Kubernetes-specific release, called Kubic, which is based on Kubernetes atop openSUSE MicroOS. But even if you aren’t developing for Kubernetes, you’ll find plenty of software and tools to work with.
And openSUSE also offers the ability to select your desktop environment, or (should you chose) a generic desktop or server (Figure 2).
Fedora
Using Fedora as a development platform just makes sense. Why? The distribution itself seems geared toward developers. With a regular, six month release cycle, developers can be sure they won’t be working with out of date software for long. This can be important, when you need the most recent tools and libraries. And if you’re developing for enterprise-level businesses, Fedora makes for an ideal platform, as it is the upstream for Red Hat Enterprise Linux. What that means is the transition to RHEL should be painless. That’s important, especially if you hope to bring your project to a much larger market (one with deeper pockets than a desktop-centric target).
Fedora also offers one of the best GNOME experiences you’ll come across (Figure 3). This translates to a very stable and fast desktops.
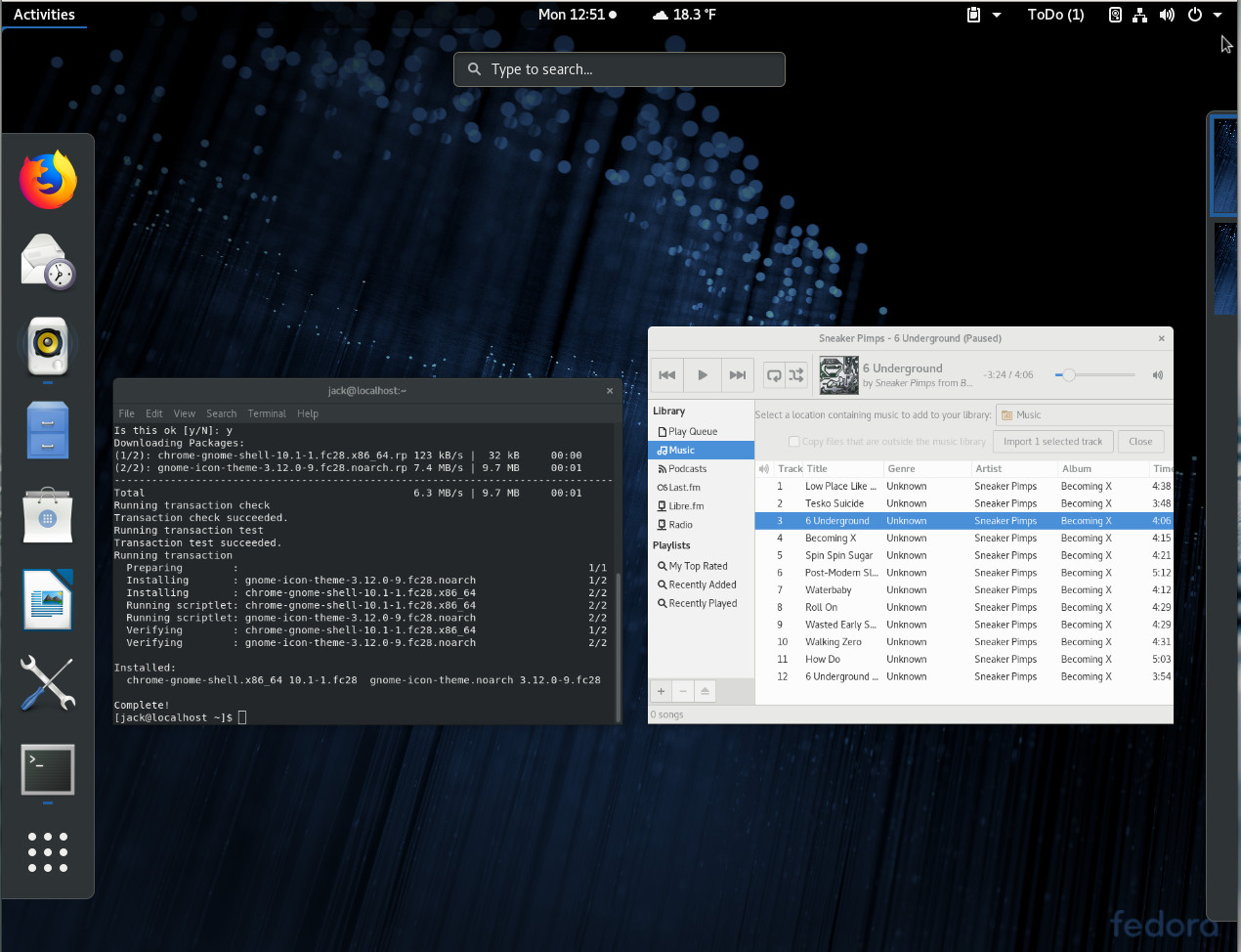
But if GNOME isn’t your jam, you can opt to install one of the Fedora spins (which includes KDE, XFCE, LXQT, Mate-Compiz, Cinnamon, LXDE, and SOAS).
Pop!_OS
I’d be remiss if I didn’t include System76’s platform, customized specifically for their hardware (although it does work fine on other hardware). Why would I include such a distribution, especially one that doesn’t really venture far away from the Ubuntu platform for which is is based? Primarily because this is the distribution you want if you plan on purchasing a desktop or laptop from System76. But why would you do that (especially given that Linux works on nearly all off-the-shelf hardware)? Because System76 sells outstanding hardware. With the release of their Thelio desktop, you have available one of the most powerful desktop computers on the market. If you’re developing seriously large applications (especially ones that lean heavily on very large databases or require a lot of processing power for compilation), why not go for the best? And since Pop!_OS is perfectly tuned for System76 hardware, this is a no-brainer.
Since Pop!_OS is based on Ubuntu, you’ll have all the tools available to the base platform at your fingertips (Figure 4).
Pop!_OS also defaults to encrypted drives, so you can trust your work will be safe from prying eyes (should your hardware fall into the wrong hands).
Manjaro
For anyone that likes the idea of developing on Arch Linux, but doesn’t want to have to jump through all the hoops of installing and working with Arch Linux, there’s Manjaro. Manjaro makes it easy to have an Arch Linux-based distribution up and running (as easily as installing and using, say, Ubuntu).
But what makes Manjaro developer-friendly (besides enjoying that Arch-y goodness at the base) is how many different flavors you’ll find available for download. From the Manjaro download page, you can grab the following flavors:
-
GNOME
-
XFCE
-
KDE
-
OpenBox
-
Cinnamon
-
I3
-
Awesome
-
Budgie
-
Mate
-
Xfce Developer Preview
-
KDE Developer Preview
-
GNOME Developer Preview
-
Architect
-
Deepin
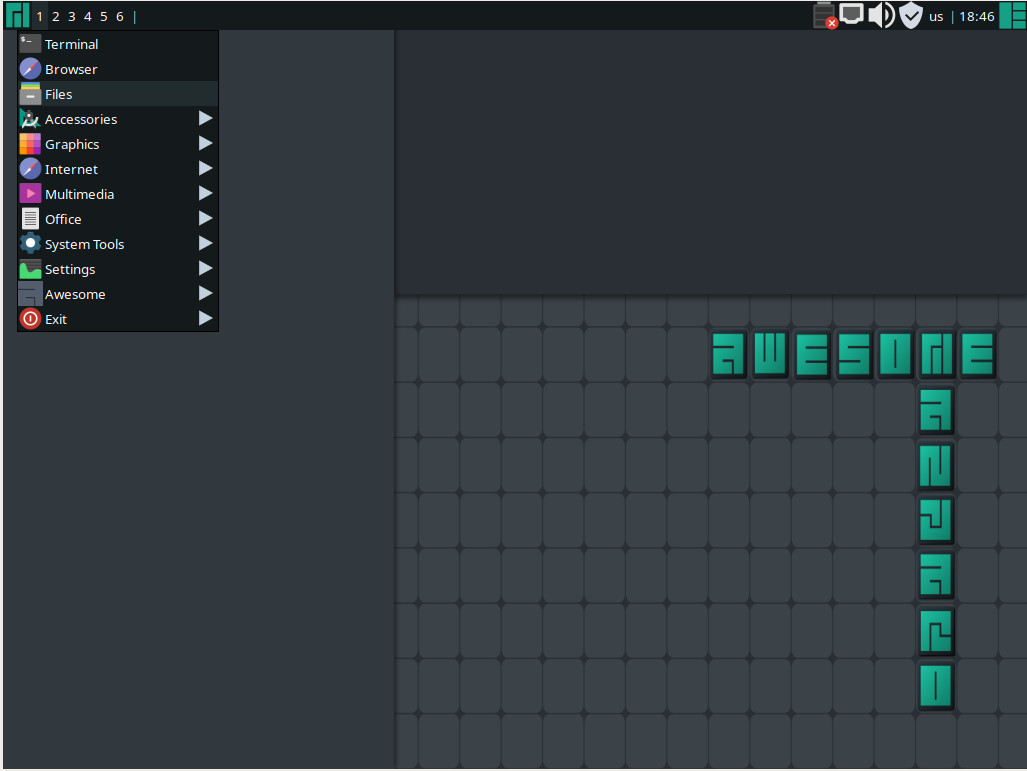
Of note are the developer editions (which are geared toward testers and developers), the Architect edition (which is for users who want to build Manjaro from the ground up), and the Awesome edition (Figure 5 – which is for developers dealing with everyday tasks). The one caveat to using Manjaro is that, like any rolling release, the code you develop today may not work tomorrow. Because of this, you need to think with a certain level of agility. Of course, if you’re not developing for Manjaro (or Arch), and you’re doing more generic (or web) development, that will only affect you if the tools you use are updated and no longer work for you. Chances of that happening, however, are slim. And like with most Linux distributions, you’ll find a ton of developer tools available for Manjaro.
Manjaro also supports the Arch User Repository (a community-driven repository for Arch users), which includes cutting edge software and libraries, as well as proprietary applications like Unity Editor or yEd. A word of warning, however, about the Arch User Repository: It was discovered that the AUR contained software considered to be malicious. So, if you opt to work with that repository, do so carefully and at your own risk.
Any Linux Will Do
Truth be told, if you’re a developer, just about any Linux distribution will work. This is especially true if you do most of your development from the command line. But if you prefer a good GUI running on top of a reliable desktop, give one of these distributions a try, they will not disappoint.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.


