An open-spec, Allwinner H6 based “Orange Pi 3” SBC has gone on sale for $30 to $40, with the latter giving you 2GB of RAM and 8GB eMMC. Other highlights: GbE, HDMI 2.0, 4x USB 3.0, WiFi-ac, and mini-PCIe.
The long-awaited Orange Pi 3 — the highest end of three Allwinner H6 based Orange Pi SBCs — has arrived for about the price of a Raspberry Pi 3. The most powerfully equipped H6-based SBC to date will attempt to take on Rockchip RK3399 based boards, including Shenzhen Xunlong’s own Orange Pi RK3999.
Ah, the age-old question: Which Linux distribution is best suited for servers? Typically, when this question is asked, the standard responses pop up:
RHEL
SUSE
Ubuntu Server
Debian
CentOS
However, in the name of opening your eyes to maybe something a bit different, I’m going to approach this a bit differently. I want to consider a list of possible distributions that are not only outstanding candidates but also easy to use, and that can serve many functions within your business. In some cases, my choices are drop-in replacements for other operating systems, whereas others require a bit of work to get them up to speed.
Some of my choices are community editions of enterprise-grade servers, which could be considered gateways to purchasing a much more powerful platform. You’ll even find one or two entries here to be duty-specific platforms. Most importantly, however, what you’ll find on this list isn’t the usual fare.
What is ClearOS? For home and small business usage, you might not find a better solution. Out of the box, ClearOS includes tools like intrusion detection, a strong firewall, bandwidth management tools, a mail server, a domain controller, and much more. What makes ClearOS stand out above some of the competition is its purpose is to server as a simple Home and SOHO server with a user-friendly, graphical web-based interface. From that interface, you’ll find an application marketplace (Figure 1), with hundreds of apps (some of which are free, whereas some have an associated cost), that makes it incredibly easy to extend the ClearOS featureset. In other words, you make ClearOS the platform your home and small business needs it to be. Best of all, unlike many other alternatives, you only pay for the software and support you need.
ClearOS Business – ideal for small businesses, due to the inclusion of paid support
To make the installation of software even easier, the ClearOS marketplace allows you to select via:
By Function (which displays apps according to task)
By Category (which displays groups of related apps)
Quick Select File (which allows you to select pre-configured templates to get you up and running fast)
In other words, if you’re looking for a Linux Home, SOHO, or SMB server, ClearOS is an outstanding choice (especially if you don’t have the Linux chops to get a standard server up and running).
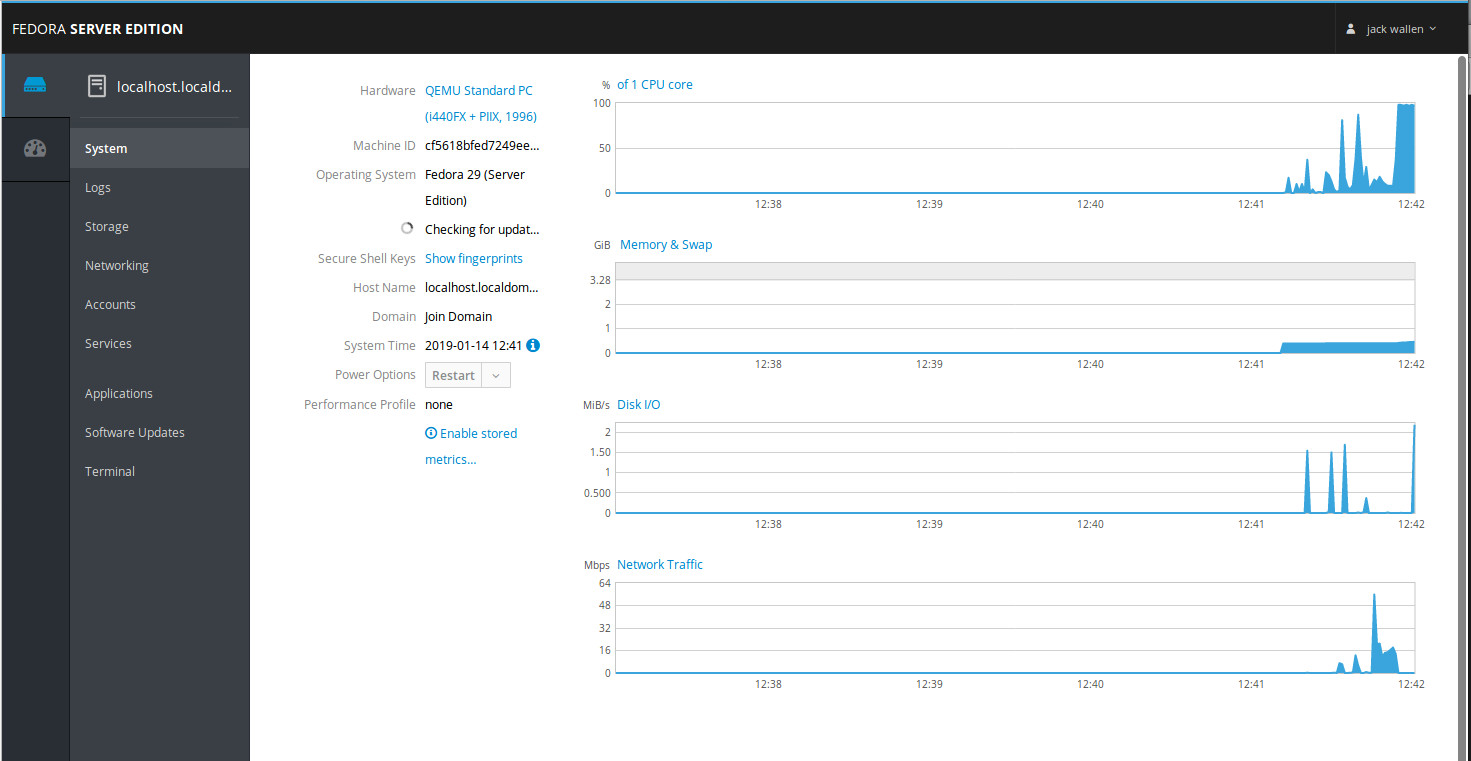
You’ve heard of Fedora Linux. Of course you have. It’s one of the finest bleeding edge distributions on the market. But did you know the developers of that excellent Fedora Desktop distribution also has a Server edition? The Fedora Server platform is a short-lifecycle, community-supported server OS. This take on the server operating system enables seasoned system administrators, experienced with any flavor of Linux (or any OS at all), to make use of the very latest technologies available in the open source community. There are three key words in that description:
Seasoned
System
Administrators
In other words, new users need not apply. Although Fedora Server is quite capable of handling any task you throw at it, it’s going to require someone with a bit more Linux kung fu to make it work and work well. One very nice inclusion with Fedora Server is that, out of the box, it includes one of the finest open source, web-based interface for servers on the market. With Cockpit (Figure 2) you get a quick glance at system resources, logs, storage, network, as well as the ability to manage accounts, services, applications, and updates.
Figure 2: Cockpit running on Fedora Server.
If you’re okay working with bleeding edge software, and want an outstanding admin dashboard, Fedora Server might be the platform for you.
NethServer is about as no-brainer of a drop-in SMB Linux server as you’ll find. With the latest iteration of NethServer, your small business will enjoy:
Built-in Samba Active Directory Controller
Seamless Nextcloud integration
Certificate management
Transparent HTTPS proxy
Firewall
Mail server and filter
Web server and filter
Groupware
IPS/IDS or VPN
All of the included features can be easily configured with a user-friendly, web-based interface that includes single-click installation of modules to expand the NethServer feature set (Figure 3) What sets NethServer apart from ClearOS is that it was designed to make the admin job easier. In other words, this platform offers much more in the way of flexibility and power. Unlike ClearOS, which is geared more toward home office and SOHO deployments, NethServer is equally at home in small business environments.
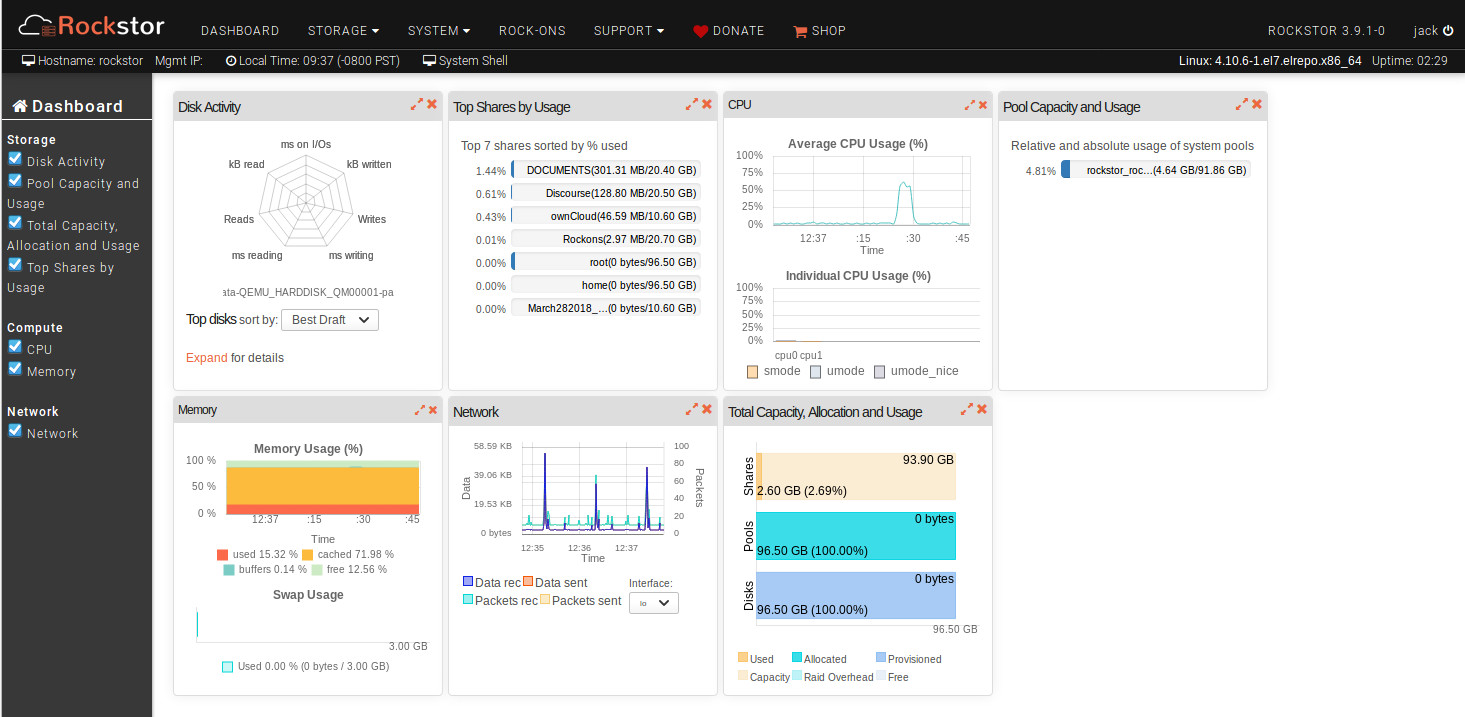
Rockstor is a Linux and Btfrs powered advanced Network Attached Storage (NAS) and Cloud storage server that can be deployed for Home, SOHO, as well as small- and mid-sized businesses alike. With Rockstor, you get a full-blown NAS/Cloud solution with a user-friendly, web-based GUI tool that is just as easy for admins to set up as it is for users to use. Once you have Rockstor deployed, you can create pools, shares, snapshots, manage replication and users, share files (with the help of Samba, NFS, SFTP, and AFP), and even extend the featureset, thanks to add-ons (called Rock-ons). The list of Rock-ons includes:
CouchPotato (Downloader for usenet and bittorrent users)
Deluge (Movie downloader for bittorrent users)
EmbyServer (Emby media server)
Ghost (Publishing platform for professional bloggers)
GitLab CE (Git repository hosting and collaboration)
Gogs Go Git Service (Lightweight Git version control server and front end)
Headphones (An automated music downloader for NZB and Torrent)
Logitech Squeezebox Server for Squeezebox Devices
MariaDB (Relational database management system)
NZBGet (Efficient usenet downloader)
OwnCloud-Official (Secure file sharing and hosting)
Plexpy (Python-based Plex Usage tracker)
Rocket.Chat (Open Source Chat Platform)
SaBnzbd (Usenet downloader)
Sickbeard (Internet PVR for TV shows)
Sickrage (Automatic Video Library Manager for TV Shows)
Sonarr (PVR for usenet and bittorrent users)
Symform (Backup service)
Rockstor also includes an at-a-glance dashboard that gives admins quick access to all the information they need about their server (Figure 4).
Zentyal is another Small Business Server that does a great job of handling multiple tasks. If you’re looking for a Linux distribution that can handle the likes of:
Directory and Domain server
Mail server
Gateway
DHCP, DNS, and NTP server
Certification Authority
VPN
Instant Messaging
FTP server
Antivirus
SSO authentication
File sharing
RADIUS
Virtualization Management
And more
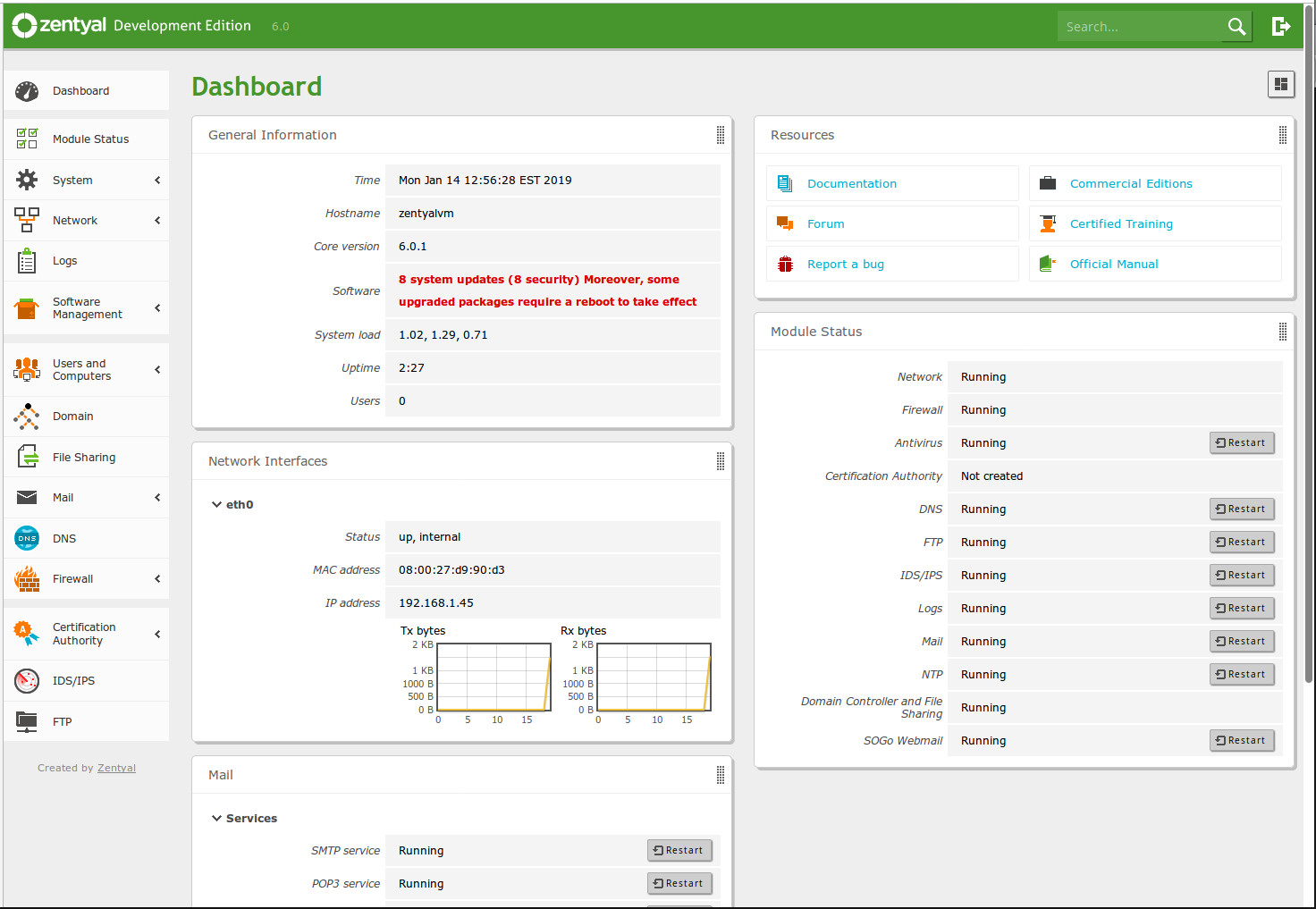
Zentyal might be your new go-to. Zentyal has been around since 2004 and is based on Ubuntu Server, so it enjoys a rock-solid base and plenty of applications. And with the help of the Zentyal dashboard (Figure 5), admins can easily manage:
System
Network
Logs
Software updates and installation
Users/groups
Domains
File sharing
Mail
DNS
Firewall
Certificates
And much more
Figure 5: The Zentyal dashboard.
Adding new components to the Zentyal server is as simple as opening the Dashboard, clicking on Software Management > Zentyal Components, selecting what you want to add, and clicking Install. The one issue you might find with Zentyal is that it doesn’t offer nearly the amount of addons as you’ll find in the likes of Nethserver and ClearOS. But the services it does offer, Zentyal does incredibly well.
Plenty More Where These Came From
This list of Linux servers is clearly not exhaustive. What it is, however, is a unique look at the top five server distributions you’ve probably not heard of. Of course, if you’d rather opt to use a more traditional Linux server distribution, you can always stick with CentOS, Ubuntu Server, SUSE, Red Hat Enterprise Linux, or Debian… most of which are found on every list of best server distributions on the market. If, however, you’re looking for something a bit different, give one of these five distos a try.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.
In this presentation, Bridget Kromhout discusses what containers and Kubernetes clusters are at a high level, looks into the practical application of open source tools to simplify cluster management, and shows how to deploy Kubernetes clusters in a repeatable and portable fashion.
“You’re probably here because you want to Kuber some netes. And I might dissuade you or I might give you some ideas about tools that will help you do that. The traditional second slide, you have to have the second slide to establish bonafides, bona fides, not sure how to say that, so you can check that off as she does not know how to say bona fides. But I’m Bridget, I live in Minneapolis. I work for Microsoft on the cloud advocacy team. I co-host the Arrested DevOps podcast with Matty Stratton, which is wonderful, because he is here and I sent him to live tweet Bryan Cantrill’s talk, because, uhh, tragically, a talk that I really would like to go to is at the same time as mine. So if any of you decide this Kubernetes is not for you and you want to hear about Rust, Bryan Cantrill is very funny.” …
“Starting with the what even are containers, how did we even get to this place? Quick show of hands, how many people are using containers in some regard right now? I’m going to say 80% of the room. Awesome. Keep your hand up if you’re using them in production. Close, maybe 65% to 70%. And how many of you are using Kubernetes in any regards right now? Maybe, it’s 40%. And in production? Yes, maybe 25%. And I think this is very natural hype cycle stuff. The future is here, like William Gibson tells us, it’s just not evenly distributed.”
Crouton used to have a target which allowed easy Cinnamon installation, but that’s no longer available. Installing Cinnamon desktop on a Chromebook using Crouton is still possible, and this article guides you through this process.
Cinnamon is a desktop environment that’s derived from Gnome 3 but using a traditional desktop layout, being the main desktop environment of the Linux Mint distribution. Since Crouton doesn’t support Linux Mint, Ubuntu 18.04 (Bionic Beaver) will be used as the Linux distribution on top of which we’ll install Cinnamon desktop.
The Linux Foundation just recently announced its 2019 events schedule, featuring all your favorite events as well as some brand-new ones to cover the latest technologies. Make plans now to speak or attend and expand your experience with open source.
The Linux Foundation’s 2019 events are projected to welcome more than 35,000 open source influencers to learn and share best practices in open source technologies ranging from operating systems, cloud applications, containers, IoT, AI, networking, security, storage, and more. New events on the schedule for this year include Cephalocon and gRPC Conf.
Submit a Proposal
If you’re interested in submitting a proposal, act soon because calls for papers for some of the earliest 2019 events are on the verge of closing. Speaking proposals are now being accepted for:
Check back soon for submission details for other upcoming events, as the calendar is regularly updated. The Linux Foundation welcomes first-time speakers and is happy to provide additional information about the submission process.
If you don’t plan to speak but do want to attend, note that events like KubeCon + CloudNativeCon Europe are expected to sell out. The recent event in Seattle was record-breaking in terms of attendance, so register early to secure your spot.
Could decluttering your work life make you more productive and happy in 2019? Considering the fact that millions of people have bought into Marie Kondo’s organization method, as described in her book “The Life-Changing Magic of Tidying Up,” and in her popular new Netfilx series, it’s an idea worth exploring.
We asked IT and business leaders for their “life-changing” hacks for filtering out the distractions and focusing on their most important work. Read on for their tips, and consider if any of these ideas can help spark more joy in your work day.
Redefine “enough”
Elene Cafasso, founder and president, Enerpace, Inc.: “Decluttering your work life begins with prioritizing. Most of us define ‘enough’ as everything. What happens when everything becomes impossible to accomplish?
Learn how to use Let’s Encrypt in this tutorial from our archives.
Back in the bad old days, setting up basic HTTPS with a certificate authority cost as much as several hundred dollars per year, and the process was difficult and error-prone to set up. Now we have Let’s Encrypt for free, and the whole thing takes just a few minutes.
Why Encrypt?
Why encrypt your sites? Because unencrypted HTTP sessions are wide open to multiple abuses:
Internet service providers lead the code-injecting offenders. How to foil their nefarious desires? Your best defense is HTTPS. Let’s review how HTTPS works.
Chain of Trust
You could set up asymmetric encryption between your site and everyone who is allowed to access it. This is very strong protection: GPG (GNU Privacy Guard, see How to Encrypt Email in Linux), and OpenSSH are common tools for asymmetric encryption. These rely on public-private key pairs. You can freely share public keys, while your private keys must be protected and never shared. The public key encrypts, and the private key decrypts.
This is a multi-step process that does not scale for random web-surfing, however, because it requires exchanging public keys before establishing a session, and you have to generate and manage key pairs. An HTTPS session automates public key distribution, and sensitive sites, such as shopping and banking, are verified by a third-party certificate authority (CA) such as Comodo, Verisign, or Thawte.
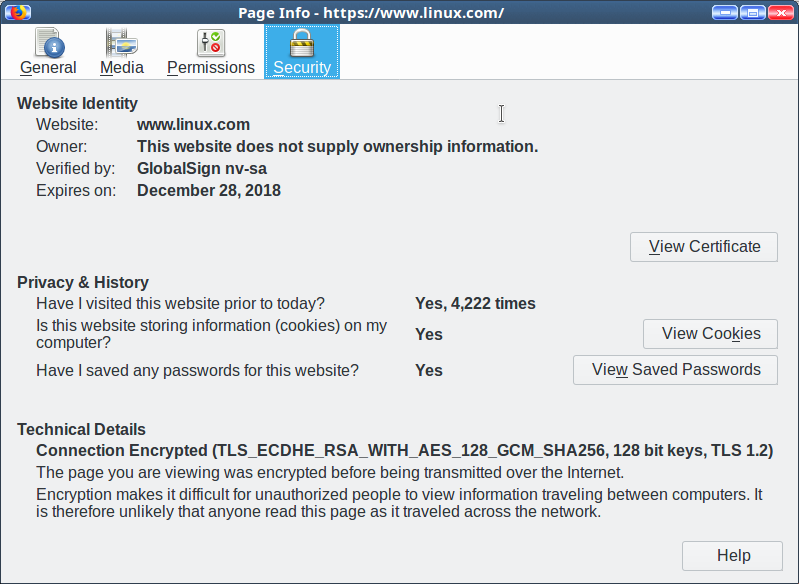
When you visit an HTTPS site, it provides a digital certificate to your web browser. This certificate verifies that your session is strongly encrypted and supplies information about the site, such as organization’s name, the organization that issued the certificate, and the name of the certificate authority. You can see all of this information, and the digital certificate, by clicking on the little padlock in your web browser’s address bar (Figure 1).
Figure 1: Click on the padlock in your web browser’s address bar for information.
The major web browsers, including Opera, Firefox, Chromium, and Chrome, all rely on the certificate authority to verify the authenticity of the site’s digital certificate. The little padlock gives the status at a glance; green = strong SSL encryption and verified identity. Web browsers also warn you about malicious sites, sites with incorrectly configured SSL certificates, and they treat self-signed certificates as untrusted.
So how do web browsers know who to trust? Browsers include a root store, a batch of root certificates, which are stored in /usr/share/ca-certificates/mozilla/. Site certificates are verified against your root store. Your root store is maintained by your package manager, just like any other software on your Linux system. On Ubuntu, they are supplied by the ca-certificates package. The root store itself is maintained by Mozilla for Linux.
As you can see, it takes a complex infrastructure to make all of this work. If you perform any sensitive online transactions, such as shopping or banking, you are trusting a whole lot of unknown people to protect you.
Encryption Everywhere
Let’s Encrypt is a global certificate authority, similar to the commercial CAs. Let’s Encrypt was founded by the non-profit Internet Security Research Group (ISRG) to make it easier to secure Websites. I don’t consider it sufficient for shopping and banking sites, for reasons which I will get to shortly, but it’s great for securing blogs, news, and informational sites that don’t have financial transactions.
There are at least three ways to use Let’s Encrypt. The best way is with the Certbot client, which is maintained by the Electronic Frontier Foundation (EFF). This requires shell access to your site.
If you are on shared hosting then you probably don’t have shell access. The easiest method in this case is using a host that supports Let’s Encrypt.
If your host does not support Let’s Encrypt, but supports custom certificates, then you can create and upload your certificate manually with Certbot. It’s a complex process, so you’ll want to study the documentation thoroughly.
When you have installed your certificate use SSL Server Test to test your site.
Let’s Encrypt digital certificates are good for 90 days. When you install Certbot it should also install a cron job for automatic renewal, and it includes a command to test that the automatic renewal works. You may use your existing private key or certificate signing request (CSR), and it supports wildcard certificates.
Limitations
Let’s Encrypt has some limitations: it performs only domain validation, that is, it issues a certificate to whoever controls the domain. This is basic SSL. It does not support Organization Validation (OV) or Extended Validation (EV) because it is not possible to automate identity validation. I would not trust a banking or shopping site that uses Let’s Encrypt– let ’em spend the bucks for a complete package that includes identity validation.
As a free-of-cost service run by a non-profit organization there is no commercial support, but only documentation and community support, both of which are quite good.
The Internet is full of malice. Everything should be encrypted. Start with Let’s Encrypt to protect your site visitors.
Learn more about Linux through the free “Introduction to Linux” course from The Linux Foundation and edX.
I still stand behind my claim that Deepin is one of the slickest and most beautiful desktop Linux distributions on the planet. Beyond that, it honestly blows away Windows 10 and macOS in terms of visual appeal. It has a number of innovative features that feel way ahead of the curve compared to more “mainstream” distros like Ubuntu and Linux Mint. Now the developers are killing some bugs and bringing a few more notable features to the OS with the new Deepin 15.9 update….
“Without data, you’re just a person with an opinion.”
Those are the words of W. Edwards Deming, the champion of statistical process control, who was credited as one of the inspirations for what became known as the Japanese post-war economic miracle of 1950 to 1960. Ironically, Japanese manufacturers like Toyota were far more receptive to Deming’s ideas than General Motors and Ford were.
Community management is certainly an art. It’s about mentoring. It’s about having difficult conversations with people who are hurting the community. It’s about negotiation and compromise. It’s about interacting with other communities. It’s about making connections. In the words of Red Hat’s Diane Mueller, it’s about “nurturing conversations.”
However, it’s also about metrics and data.
Some have much in common with software development projects more broadly. Others are more specific to the management of the community itself. I think of deciding what to measure and how as adhering to five principles.
Learn the fundamentals of sorting and de-duplicating text on the command line.
If you’ve been using the command line for a long time, it’s easy to take the commands you use every day for granted. But, if you’re new to the Linux command line, there are several commands that make your life easier that you may not stumble upon automatically. In this article, I cover the basics of two commands that are essential in anyone’s arsenal: sort and uniq.
The sort command does exactly what it says: it takes text data as input and outputs sorted data. There are many scenarios on the command line when you may need to sort output, such as the output from a command that doesn’t offer sorting options of its own (or the sort arguments are obscure enough that you just use the sort command instead). In other cases, you may have a text file full of data (perhaps generated with some other script), and you need a quick way to view it in a sorted form.
Let’s start with a file named “test” that contains three lines: