
Simplify how you interact with containers by incorporating pods, init containers, additional image stores, system reset, and play kube into your work.
Read More at Enable Sysadmin
Simplify how you interact with containers by incorporating pods, init containers, additional image stores, system reset, and play kube into your work.
Read More at Enable Sysadmin

First in a regular series of blogs highl
Click to Read More at Oracle Linux Kernel Development

This is a classic article written by Jack Wallen from the Linux.com archives. For more great SysAdmin tips and techniques check out our free intro to Linux course.
Many years ago, when I first began with Linux, installing applications and keeping a system up to date was not an easy feat. In fact, if you wanted to tackle either task you were bound for the command line. For some new users this left their machines outdated or without applications they needed. Of course, at the time, most everyone trying their hand at Linux knew they were getting into something that would require some work. That was simply the way it was. Fortunately times and Linux have changed. Now Linux is exponentially more user friendly – to the point where so much is automatic and point and click – that today’s Linux hardly resembles yesterday’s Linux.
But even though Linux has evolved into the user-friendly operating system it is, there are still some systems that are fundamentally different than their Windows counterparts. So it is always best to understand those systems in order to be able to properly use those system. Within the confines of this article you will learn how to keep your Linux system up to date. In the process you might also learn how to install an application or two.
There is one thing to understand about updating Linux: Not every distribution handles this process in the same fashion. In fact, some distributions are distinctly different down to the type of file types they use for package management.
Ubuntu and Debian use .deb
Fedora, SuSE, and Mandriva use .rpm
Slackware uses .tgz archives which contain pre-built binaries
And of course there is also installing from source or pre-compiled .bin or .package files.
apt-get: Command line tool.
Update Manager: GUI tool.
Security updates: Daily
Non-security updates: Weekly
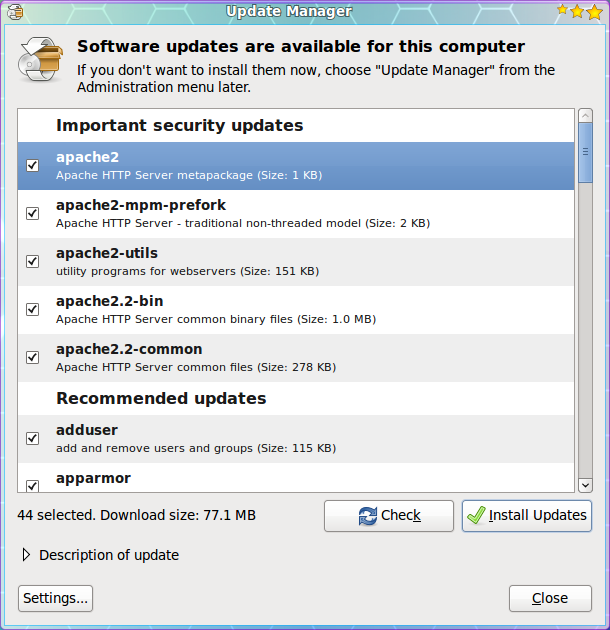
If you want to manually check for updates, you can do this by clicking the Administration sub-menu of the System menu and then selecting the Update Manager entry. When the Update Manager opens click the Check button to see if there are updates available.
Check the updates you want to install. By default all updates are selected.
Click the Install Updates button.
Enter your user (sudo) password.
Click OK.
The updates will proceed and you can continue on with  your work. Now some updates may require either you to log out of your desktop and log back in, or to reboot the machine. There are is a new tool in development (Ksplice) that allow even the update of a kernel to not require a reboot.
Once all of the updates are complete the Update Manage main window will return reporting that Your system is up to date.
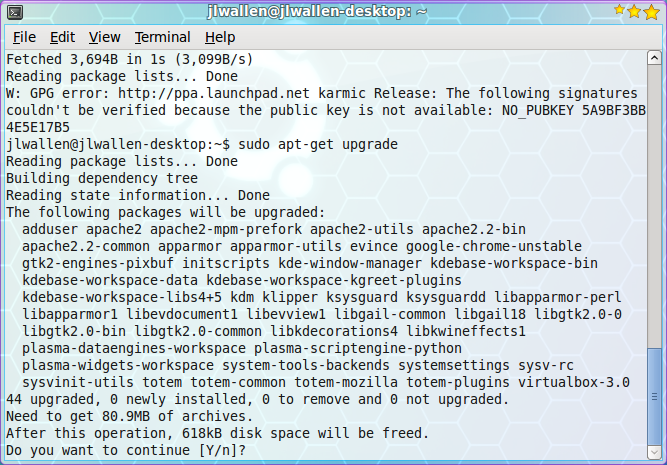
Now let’s take a look at the command line tools for updating your system. The Ubuntu package management system is called apt. Apt is a very powerful tool that can completely manage your systems packages via command line. Using the command line tool has one drawback – in order to check to see if you have updates, you have to run it manually. Let’s take a look at how to update your system with the help of Apt. Follow these steps:
Open up a terminal window.
Issue the command sudo apt-get upgrade.
Enter your user’s password.
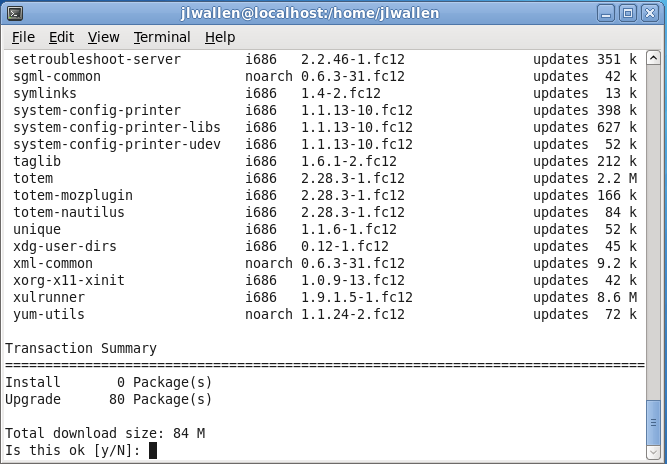
Look over the list of available updates (see Figure 2) and decide if you want to go through with the entire upgrade.
To accept all updates click the ‘y’ key (no quotes) and hit Enter.
Watch as the update happens.
That’s it. Your system is now up to date. Let’s take a look at how the same process happens on Fedora (Fedora 12 to be exact).
yum: Command line tool.
GNOME (or KDE) PackageKit: GUI tool.
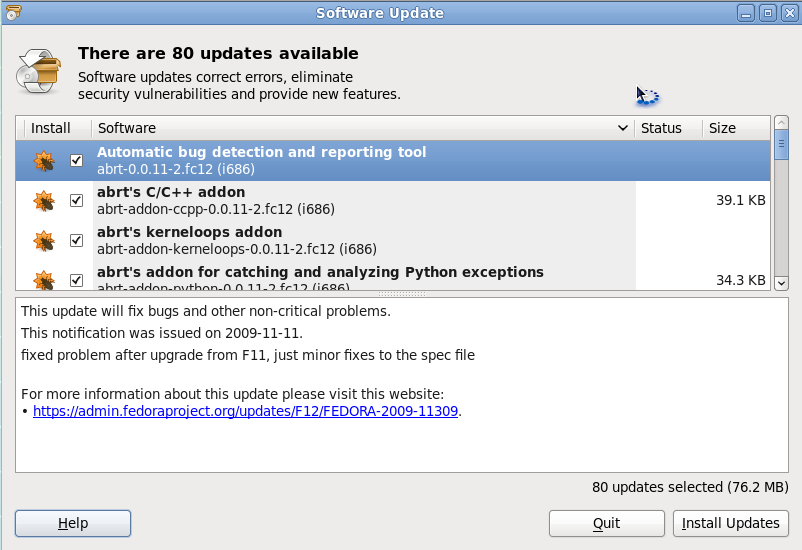
Depending upon your desktop, you will either use the GNOME or the KDE front-end for PackageKit. In order to open up this tool you simply go to the Administration sub-menu of the System menu and select the Software Update entry.  When the tool opens (see Figure 3) you will see the list of updates. To get information about a particular update all you need to do is to select a specific package and the information will be displayed in the bottom pane.
To go ahead with the update click the Install Updates button. As the process happens a progress bar will indicate where GNOME (or KDE) PackageKit is in the steps. The steps are:
Resolving dependencies.
Downloading packages.
Testing changes.
Installing updates.
When the process is complete, GNOME (or KDE) PackageKit will report that your system is update. Click the OK button when prompted.
Now let’s take a look at upgrading Fedora via the command line. As stated earlier, this is done with the help of the yum command. In order to take care of this, follow these steps:
Open up a terminal window (Do this by going to the System Tools sub-menu of the Applications menu and select Terminal).
Enter the su command to change to the super user.
Type your super user password and hit Enter.
Issue the command yum update and yum will check to see what packages are available for update.
Look through the listing of updates (see Figure 4).
If you want to go through with the update enter ‘y’ (no quotes) and hit Enter.
Sit back and watch the updates happen.
Exit out of the root user command prompt by typing “exit” (no quotes) and hitting Enter.
Close the terminal when complete.
Your Fedora system is now up to date.
Granted only two distributions were touched on here, but this should illustrate how easily a Linux installation is updated. Although the tools might not be universal, the concepts are. Whether you are using Ubuntu, OpenSuSE, Slackware, Fedora, Mandriva, or anything in-between, the above illustrations should help you through updating just about any Linux distribution. And hopefully this tutorial helps to show you just how user-friendly the Linux operating system has become.
Ready to continue your Linux journey? Check out our free intro to Linux course!
The post Classic SysAdmin: Linux 101: Updating Your System appeared first on Linux Foundation.

Here at The Linux Foundation’s blog, we share content from our projects, such as this article by Joel Hans from the Cloud Native Computing Foundation’s blog.
The telecommunications industry is the backbone of today’s increasingly-digital economies, but it faces a difficult new challenge in evolving to meet modern infrastructure practices. How did telecommunications get itself into this situation? Because the risks of incidents or downtime are so severe, the industry has focused almost exclusively on system designs that minimize risk and maximize reliability. That’s fantastic for mission-critical services, whether public air traffic control or private high-speed banking, but it emphasizes stability over productivity and the adoption of new technologies that might make their operations more resilient and performant.
Telecommunications is playing catch-up on cloud native technology, and the downstream effects are starting to show. These organizations are now behind the times on the de facto choices for enterprise and IT, which means they’re less likely to recruit the top-tier engineering talent they need. In increasingly competitive landscapes, they need to escalate productivity and deploy new telephony platforms to market faster, not get quagmired in old custom solutions built in-house.
To make that leap from internally-trusted to industry-trusted tooling, telecommunications organizations need confidence that they’re on track to properly evolve their virtual network function (VNF) infrastructure to enable cloud native functions using Kubernetes. That’s where CNCF aims to help.
A cloud native network function (CNF) is an application that implements or facilitates network functionality in a cloud native way, developed using standardized principles and consisting of at least one microservice.
And the CNF Test Suite (cncf/cnf-testsuite) is an open source test suite for telcos to know exactly how cloud native their CNFs are. It’s designed for telecommunications developers and network operators, building with Kubernetes and other cloud native technology, to validate how well they’re following cloud native principles and best practices, like immutable infrastructure, declarative APIs, and a “repeatable deployment process.”
The CNCF is bringing together the Telecom User Group (TUG) and the Cloud Native Network Function Working Group (CNF WG) to implement the CNF Test Suite, which helps telco developers and ops teams build faster feedback loops thanks to the suite’s flexible testing and optimized execution time. Because it can be integrated into any CI/CD pipeline, whether in development or pre-production checks, or run as a standalone test for a single CNF, telecommunications development teams get at-a-glance understanding of how their new deployments align with the cloud native ecosystem, including CNCF-hosted projects, technologies, and concepts.
It’s a powerful answer to a difficult question: How cloud native are we?
The CNF Test Suite leverages 10 CNCF-hosted projects and several open source tools. A modified version of CoreDNS is used as an example CNF for end users to get familiar with the test suite in five steps, and Prometheus is utilized in an observability test to check the best practice for CNFs to actively expose metrics. And it packages other upstream tools, like OPA Gatekeeper, Helm linter, and Promtool to make installation, configuration, and versioning repeatable. The CNF Test Suite team is also grateful to contributions from Kyverno on security tests, LitmusChaos for resilience tests, and Kubescope for security policies.
The minimal install for the CNF Test Suite requires only a running Kubernetes cluster, kubectl, curl, and helm, and even supports running CNF tests on air-gapped machines or those who might need to self-host the image repositories. Once installed, you can use an example CNF or bring your own—all you need is to supply the .yml file and run `cnf-testsuite all` to run all the available tests. There’s even a quick five-step process for deploying the suite and getting recommendations in less than 15 minutes.
At the start of 2022, the CNF Test Suite can run approximately 60 workload tests, which are segmented into 7 different categories.
Compatibility, Installability & Upgradability: CNFs should work with any Certified Kubernetes product and any CNI-compatible network that meet their functionality requirements while using standard, in-band deployment tools such as Helm (version 3) charts. The CNF Test Suite checks whether the CNF can be horizontally and vertically scaled using `kubectl` to ensure it can leverage Kubernetes’ built-in functionality.
Microservice: The CNF should be developed and delivered as a microservice for improved agility, or the development time required between deployments. Agile organizations can deploy new features more frequently or allow multiple teams to safely deploy patches based on their functional area, like fixing security vulnerabilities, without having to sync with other teams first.
State: A cloud native infrastructure should be immutable, environmentally-agnostic, and resilient to node failure, which means properly managing configuration, persistent data, and state. A CNF’s configuration should be stateless, stored in a custom resource definition or a separate database over local storage, with any persistent data managed by StatefulSets. Separate stateful and stateless information makes for infrastructure that’s easily reproduced, consistent, disposable, and always deployed in a repeatable way.
Reliability, Resilience & Availability: Reliability in telco infrastructure is the same as standard IT—it needs to be highly secure and reliable and support ultra-low latencies. Cloud native best practices try to reduce mean time between failure (MTBF) by relying on redundant subcomponents with higher serviceability (mean time to recover (MTTR)), and then testing those assumptions through chaos engineering and self-healing configurations. The Test Suite uses a type of chaos testing to ensure CNFs are resilient to the inevitable failures of public cloud environments or issues on an orchestrator level, such as what happens when pods are unexpectedly deleted or run out of computing resources. These tests ensure CNFs meet the telco industry’s standards for reliability on non-carrier-grade shared cloud hardware/software platforms.
Observability & Diagnostics: Each piece of production cloud native infrastructure must make its internal states observable through metrics, tracing, and logging. The CNF Test suite looks for compatibility with Fluentd, Jaeger, Promtool, Prometheus, and OpenMetrics, which help DevOps or SRE teams maintain, debug, and gather insights about the health of their production environments, which must be versioned, maintained in source control, and altered only through deployment pipelines.
Security: Cloud native security requires attention from experts at the operating system, container runtime, orchestration, application, and cloud platform levels. While many of these fall outside the scope of the CNF Test Suite, it still validates whether containers are isolated from one another and the host, do not allow privilege escalation, have defined resource limits, and are verified against common CVEs.
Configuration: Teams should manage a CNF’s configuration in a declarative manner—using ConfigMaps, Operators, or other declarative interfaces—to design the desired outcome, not how to achieve said outcome. Declarative configuration doesn’t have to be executed to be understood, making it far less prone to error than imperative configuration or even the most well-maintained sequences of `kubectl` commands.
After deploying numerous tests in each category, the CNF Test Suite outputs flexible scoring and suggestions for remediation for each category (or one category if you chose that in the CLI), giving you practical next steps on improving your CNF to better follow cloud native best practices. It’s a powerful—and still growing—solution for the telecommunications industry to embrace the cloud native in a way that’s controllable, observable, and validated by all the expertise under the CNCF umbrella.
The Test Suite initiative will continue to work closely with the Telecom User Group (TUG) and the Cloud Native Network Function Working Group (CNF WG), collecting feedback based on real-world use cases and evolving the project. As the CNF WG publishes more recommended practices for cloud native telcos, the CNF Test Suite team will add more tests to validate each.
In fact, v0.26.0, released on February 25, 2022, includes six new workload tests, bug fixes, and improved documentation around platform tests. If you’d like to get involved and shape the future of the CNF Test Suite, there are already several ways to provide feedback or contribute code, documentation, or example CNFs:
Visit the CNF Test Suite on GitHub
Continue the conversation on Slack (#cnf-testsuite-dev)
Attend CNF Test Suite Contributor calls on Thursdays at 15:15 UTC
Join the CNF Working Group meetings on Mondays at 16:00 UTC
The CNF Test Suite is just the first exciting step in the upcoming Cloud Native Network Function (CNF) Certification Program. We’re looking forward to making the CNF Test Suite the de facto tool for network equipment providers and CNF development teams to prove—and then certify—that they’re adopting cloud native best practices in new products and services.
The wins for the telecommunications industry are clear:
Providers get verification that their cloud native applications and architectures adhere to cloud native best practices.
Their customers get verification that the cloud native services or networks they’re procuring are actually cloud native.
And they both get even better reliability, reduced risk, and lowered capital/operating costs.
We’re planning on supporting any product that runs in a certified Kubernetes environment to make sure organizations build CNFs that are compatible with any major public cloud providers or on-premises environments. We haven’t yet published the certification requirements, but they will be similar to the k8s-conformance process, where you can submit results via pull request and receive updates on your certification process over email.
As the CNF Certification Program develops, both the TUG and CNF-WG will engage with organizations that use the Test Suite heavily to make improvements and stay up-to-date on the latest cloud native best practices. We’re excited to see how the telecommunications industry evolves by adopting more cloud native principles, like loosely-coupled systems and immutability, and gathering proof of their hard work via the CNF Test Suite. That’s how we ensure a complex and essential industry makes the right next steps away toward the best technology infrastructure has to offer—without sacrificing an inch on reliability.
To take the next steps with the CNF Test Suite and prepare your organization for the upcoming CNF Certification Program, schedule a personalized CNF Test Suite demo or attend Cloud Native Telco Day, a co-located Event at KubeCon + CloudNativeCon Europe 2022 on May 16, 2022.
The post Looking Ahead: The CNF Certification Program appeared first on Linux Foundation.
For this three-part series, we implemented a ‘pedal to the metal’ GPIO driven, flashing of a LED, in the context of a Linux kernel module for the NVIDIA Jetson Nano development board (kernel-based v4.9.294, arm64) in my favorite programming language … Ada!
You can find the whole project published at https://github.com/ohenley/adacore_jetson. It is known to build and run properly. All instructions to be up and running in 5 minutes are included in the accompanying front-facing README.md. Do not hesitate to fill a GitHub issue if you find any problem.
Disclaimer: This text is meant to appeal to both Ada and non-Ada coders. Therefore I try to strike a balance between code story simplicity, didactic tractability, and features density. As I said to a colleague, this is the text I would have liked to cross before starting this experiment.
Our code boundary to the Linux kernel C methods lies in kernel.ads. For an optional “adaptation” opportunity, kernel.adb exists before breaking into the concrete C binding. Take printk (printf equivalent in kernel space) for example. In C, you would call printk(“hello\n”). Ada strings are not null-terminated, they are an array of characters. To make sure the passed Ada string stays valid on the C side, you expose specification signatures .ads that make sense when programming from an Ada point of view and “adapt” in body implementation .adb before calling directly into the binding. Strictly speaking, our exposed Ada Printk would qualify as a “thick” binding even though the adaptation layer is minimal. This is in opposition to a “thin” binding which is really a one-to-one mapping on the C signature as implemented by Printk_C.
-- kernel.ads
procedure Printk (S : String); -- only this is visible for clients of kernel
-- kernel.adb
procedure Printk_C (S : String) with -- considered a thin binding
Import => true,
Convention => C,
External_Name => "printk";
procedure Printk (S : String) is -- considered a thick binding
begin
Printk_C (S & Ascii.Lf & Ascii.Nul); -- because we ‘mangle’ for Ada comfort
end;
Binding to a wrapped C macro or static inline is often convenient, potentially makes you inherit fixes, upgrades happening inside/under the macro implementation and are, depending on the context, potentially more portable. create_singlethread_workqueue used in printk_wq.c as found in Part 1 makes a perfect example. Our driver has a C home in main.c. You create a C wrapping function calling the macro.
/* main.c */
extern struct workqueue_struct * wrap_create_singlethread_wq (const char* name)
{
return create_singlethread_workqueue(name); /* calling the macro */
}
You then bind to this wrapper on the Ada side and use it. Done.
-- kernel.ads
function Create_Singlethread_Wq (Name : String) return Workqueue_Struct_Access with
Import => True,
Convention => C,
External_Name => "wrap_create_singlethread_wq";
-- flash_led.adb
...
Wq := K.Create_Singlethread_Wq ("flash_led_work");
Sometimes a macro called on the C side creates stuff, in place, which you end up needing on the Ada side. You can probably always bind to this resource but I find it often impedes code story. Take DECLARE_DELAYED_WORK(dw, delayed_work_cb) for example. From an outside point of view, it implicitly creates struct delayed_work dw in place.
/* https://elixir.bootlin.com/linux/v4.9.294/source/include/linux/workqueue.h */
#define DECLARE_DELAYED_WORK(n, f) \
struct delayed_work n = __DELAYED_WORK_INITIALIZER(n, f, 0)
Using this macro, the only way I found to get a hold of dw from Ada without crashing (returning dw from a wrapper never worked) was to globally call DECLARE_DELAYED_WORK(n, f) in main.c and then bind only to dw. Having to maintain this from C, making it magically appear in Ada felt “breadboard wiring” to me. In the code repository, you will find that we fully reconstructed this macro under the procedure of the same name Declare_Delayed_Work.
Most published Ada to C bindings implement full definition parity. This is an ideal situation in most cases but it also comes with complexity, may generate many 3rd party files, sometimes buried deep, out-of-sync definitions, etc. What can you do when complete bindings are missing or you just want to move lean and fast? If you are making a prototype, you want minimal dependencies, the binding part is peripheral eg. you may only need a quick native window API. You get the point.
Depending on the context you do not always need the full type definitions to get going. Anytime you are strictly dealing with a handle pointer (not owning the memory), you can take a shortcut. Let’s bind to gpio_get_value to illustrate. Again, I follow and layout all C signatures found in the kernel sources leading to concrete stuff, where we can bind.
/* https://elixir.bootlin.com/linux/v4.9.294/source(-) */
/* (+)include/linux/gpio.h */
static inline int gpio_get_value(unsigned int gpio)
{
return __gpio_get_value(gpio);
}
/* (+)include/asm-generic/gpio.h */
static inline int __gpio_get_value(unsigned gpio)
{
return gpiod_get_raw_value(gpio_to_desc(gpio));
}
/* (+)include/linux/gpio/consumer.h */
struct gpio_desc *gpio_to_desc(unsigned gpio); /* bindable */
int gpiod_get_raw_value(const struct gpio_desc *desc); /* bindable */
/* (+)drivers/gpio/gpiolib.h */
struct gpio_desc {
struct gpio_device *gdev;
unsigned long flags;
...
const char *name;
};
Inspecting the C definitions we find that gpiod_get_raw_value and gpio_to_desc are our available functions for binding. We note gpio_to_desc uses a transient pointer of type gpio_desc *. Because we do not touch or own a full gpio_desc instance we can happily skip defining it in full (and any dependent leads eg. gpio_device).
By declaring type Gpio_Desc_Acc is new System.Address; we create an equivalent to gpio_desc *. After all, a C pointer is a named system address. We now have everything we need to build our Ada version of gpio_get_value.
-- kernel.ads
package Ic renames Interfaces.C;
function Gpio_Get_Value (Gpio : Ic.Unsigned) return Ic.Int; -- only this is visible for clients of kernel
-- kernel.adb
type Gpio_Desc_Acc is new System.Address; -- shortcut
function Gpio_To_Desc_C (Gpio : Ic.Unsigned) return Gpio_Desc_Acc with
Import => True,
Convention => C,
External_Name => "gpio_to_desc";
function Gpiod_Get_Raw_Value_C (Desc : Gpio_Desc_Acc) return Ic.Int with
Import => True,
Convention => C,
External_Name => "gpiod_get_raw_value";
function Gpio_Get_Value (Gpio : Ic.Unsigned) return Ic.Int is
Desc : Gpio_Desc_Acc := Gpio_To_Desc_C (Gpio);
begin
return Gpiod_Get_Raw_Value_C (Desc);
end;
In most production contexts we cannot recommend reconstructing unbindable kernel API calls in Ada. Wrapping the C macro or static inline is definitely easier, safer, portable and maintainable. The following goes full blown Ada for the sake of illustrating some interesting nuts and bolts and to show that it is always possible.
Given the will power you can always reconstruct the targeted macro or static inline in Ada. Let’s come back to create_singlethread_workqueue. If you take the time to expand its macro using GCC this is what you get.
$ gcc -E [~ 80_switches_for_valid_ko] printk_wq.c
...
wq = __alloc_workqueue_key(("%s"),
(WQ_UNBOUND |
__WQ_ORDERED |
__WQ_ORDERED_EXPLICIT |
(__WQ_LEGACY | WQ_MEM_RECLAIM)),
(1),
((void *)0),
((void *)0),
"my_wq");
All arguments are straightforward to map except the OR‘ed flags. Let’s search the kernel sources for those flags.
/* https://elixir.bootlin.com/linux/v4.9.294/source/include/linux/workqueue.h */
enum {
WQ_UNBOUND = 1 << 1,
...
WQ_POWER_EFFICIENT = 1 << 7,
__WQ_DRAINING = 1 << 16,
...
__WQ_ORDERED_EXPLICIT = 1 << 19,
WQ_MAX_ACTIVE = 512,
WQ_MAX_UNBOUND_PER_CPU = 4,
WQ_DFL_ACTIVE = WQ_MAX_ACTIVE / 2,
};
Here are our design decisions for reconstruction
Because we do not use these flags elsewhere in our code base, the occasion is perfect to show that in Ada we can keep all this modeling local to our unique function using it.
-- kernel.ads
package Ic renames Interfaces.C;
type Wq_Struct_Access is new System.Address; -- shortcut
type Lock_Class_Key_Access is new System.Address; -- shortcut
Null_Lock : Lock_Class_Key_Access :=
Lock_Class_Key_Access (System.Null_Address); -- typed ((void *)0) equiv.
-- kernel.adb
type Bool is (NO, YES) with Size => 1; -- enum holding on 1 bit
for Bool use (NO => 0, YES => 1); -- "represented" by 0, 1 too
function Alloc_Workqueue_Key_C ...
External_Name => "__alloc_workqueue_key"; -- thin binding
function Create_Singlethread_Wq (Name : String) return Wq_Struct_Access is
type Workqueue_Flags is record
...
WQ_POWER_EFFICIENT : Bool;
WQ_DRAINING : Bool;
...
end record with Size => Ic.Unsigned'Size;
for Workqueue_Flags use record
...
WQ_POWER_EFFICIENT at 0 range 7 .. 7;
WQ_DRAINING at 0 range 16 .. 16;
...
end record;
Flags : Workqueue_Flags := (WQ_UNBOUND => YES,
WQ_ORDERED => YES,
WQ_ORDERED_EXPLICIT => YES,
WQ_LEGACY => YES,
WQ_MEM_RECLAIM => YES,
Others => NO);
Wq_Flags : Ic.Unsigned with Address => Flags'Address;
begin
return Alloc_Workqueue_Key_C ("%s", Wq_Flags, 1, Null_Lock, "", Name);
end;
Wq_Flags : Ic.Unsigned with Address => Flags'Address; -- voila!The core work of the raw_io version happens in Set_Gpio. Using Ioremap, we retrieve the kernel mapped IO memory location for the GPIO_OUT register physical address. We then write the content of our Gpio_Control to this IO memory location through Io_Write_32.
-- kernel.ads
type Iomem_Access is new System.Address;
-- led.adb
package K renames Kernel;
package C renames Controllers;
procedure Set_Gpio (Pin : C.Pin; S : Led.State) is
function Bit (S : Led.State) return C.Bit renames Led.State'Enum_Rep;
Base_Addr : K.Iomem_Access;
Control : C.Gpio_Control := (Bits => (others => 0),
Locks => (others => 0));
Control_C : K.U32 with Address => Control'Address;
begin
...
Control.Bits (Pin.Reg_Bit) := Bit (S); -- set the GPIO flags
...
Base_Addr := Ioremap (C.Get_Register_Phys_Address (Pin.Port, C.GPIO_OUT),
Control_C'Size); -- get kernel mapped register addr.
K.Io_Write_32 (Control_C, Base_Addr); -- write our GPIO flags to this addr.
...
end;
Let’s take the hard paths of full reconstruction to illustrate interesting stuff. We first implement ioremap. On the C side we find
/* https://elixir.bootlin.com/linux/v4.9.294/source(-) */
/* (+)arch/arm64/include/asm/io.h */
#define ioremap(addr, size) \
__ioremap((addr), (size), __pgprot(PROT_DEVICE_nGnRE))
extern void __iomem *__ioremap(phys_addr_t phys_addr, size_t size, pgprot_t prot);
Here we are both lucky and unlucky. __ioremap is low hanging while __pgprot(PROT_DEVICE_nGnRE) turns out to be a rabbit hole. I skip the intermediate expansion by reporting the final result
$ gcc -E [~ 80_switches_for_valid_ko] test_using_ioremap.c
…
void* membase = __ioremap(
(phys_addr + offset),
(4),
((pgprot_t) {
(((((((pteval_t)(3)) << 0) |
(((pteval_t)(1)) << 10) |
(((pteval_t)(3)) << 8)) |
(arm64_kernel_unmapped_at_el0() ? (((pteval_t)(1)) << 11) : 0)) |
(((pteval_t)(1)) << 53) |
(((pteval_t)(1)) << 54) |
(((pteval_t)(1)) << 55) |
((((pteval_t)(1)) << 51)) |
(((pteval_t)((1))) << 2)))
}))
Searching for definitions in the kernel sources: (meaningful sampling only)
/* https://elixir.bootlin.com/linux/v4.9.294/source(-) */
/* (+)arch/arm64/include/asm/pgtable-hwdef.h */
#define PTE_TYPE_MASK (_AT(pteval_t, 3) << 0)
...
#define PTE_NG (_AT(pteval_t, 1) << 11)
...
#define PTE_ATTRINDX(t) (_AT(pteval_t, (t)) << 2)
/* (+)arch/arm64/include/asm/mmu.h */
static inline bool arm64_kernel_unmapped_at_el0(void)
{
return IS_ENABLED(CONFIG_UNMAP_KERNEL_AT_EL0) &&
cpus_have_const_cap(ARM64_UNMAP_KERNEL_AT_EL0);
}
/* (+)arch/arm64/include/asm/pgtable-prot.h */
#define PTE_DIRTY (_AT(pteval_t, 1) << 55)
/* (+)arch/arm64/include/asm/memory.h */
#define MT_DEVICE_nGnRE 1
The macro pattern _AT(pteval_t, x) can be cleared right away. IIUC, it serves to handle calling both from assembly and C. When you are concerned by the C case, like we do, it boils down to x, eg. ((pteval_t)(1)) << 10) becomes 1 << 10.
arm64_kernel_unmapped_at_el0 is in part ‘kernel configuration dependant’, defaulting to ‘yes’, so let’s simplify our job and bring it in, PTE_NG which is the choice ? (((pteval_t)(1)) << 11), for all cases.
(((pteval_t)((1))) << 2))) turns out to be PTE_ATTRINDX(t) with MT_DEVICE_nGnRE as input. Inspecting the kernel sources, there are four other values intended as input to PTE_ATTRINDX(t). PTE_ATTRINDX behaves like a function so let implement it as such.
type Pgprot_T is mod 2**64; -- type will hold on 64 bits
type Memory_T is range 0 .. 5;
MT_DEVICE_NGnRnE : constant Memory_T := 0;
MT_DEVICE_NGnRE : constant Memory_T := 1;
...
MT_NORMAL_WT : constant Memory_T := 5;
function PTE_ATTRINDX (Mt : Memory_T) return Pgprot_T is
(Pgprot_T(Mt * 2#1#e+2)); -- base # based_integer # exponent
Here I want to show another way to replicate C behavior, this time using bitwise operations. Something like PTE_TYPE_MASK value ((pteval_t)(3)) << 0 cannot be approached like we did before. 3 takes two bits and is somewhat a magic number. What we can do is improve on the representation. We are doing bit masks so why not express using binary numbers directly. It even makes sense graphically.
PTE_VALID : Pgprot_T := 2#1#e+0;
...
PTE_TYPE_MASK : Pgprot_T := 2#1#e+0 + 2#1#e+1; -- our famous 3
...
PTE_HYP_XN : Pgprot_T := 2#1#e+54;
-- kernel.ads
type Phys_Addr_T is new System.Address;
type Iomem_Access is new System.Address;
-- kernel.adb
function Ioremap (Phys_Addr : Phys_Addr_T;
Size : Ic.Size_T) return Iomem_Access is
...
Pgprot : Pgprot_T := (PTE_TYPE_MASK or
PTE_AF or
PTE_SHARED or
PTE_NG or
PTE_PXN or
PTE_UXN or
PTE_DIRTY or
PTE_DBM or
PTE_ATTRINDX (MT_DEVICE_NGnRE));
begin
return Ioremap_C (Phys_Addr, Size, Pgprot);
end;
So what is interesting here?
Now we give a look at ioread32 and iowrite32. Turns out those are, again, a cascade of static inline and macros ending up directly emitting GCC assembly directives (detailing only iowrite32).
/* https://elixir.bootlin.com/linux/v4.9.294/source(-) */
/* (+)include/asm-generic/io.h */
static inline void iowrite32(u32 value, volatile void __iomem *addr)
{
writel(value, addr);
}
/* (+)include/asm/io.h */
#define writel(v,c) ({ __iowmb(); writel_relaxed((v),(c)); })
#define __iowmb() wmb()
/* (+)include/asm/barrier.h */
#define wmb() dsb(st)
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
/* (+)arch/arm64/include/asm/io.h */
#define writel_relaxed(v,c) \
((void)__raw_writel((__force u32)cpu_to_le32(v),(c)))
static inline void __raw_writel(u32 val, volatile void __iomem *addr)
{
asm volatile("str %w0, [%1]" : : "rZ" (val), "r" (addr));
}
In Ada it becomes
with System.Machine_Code
...
procedure Io_Write_32 (Val : U32; Addr : Iomem_Access) is
use System.Machine_Code;
begin
Asm (Template => "dsb st",
Clobber => "memory",
Volatile => True);
Asm (Template => "str %w0, [%1]",
Inputs => (U32'Asm_Input ("rZ", Val),
Iomem_Access'Asm_Input ("r", Addr)),
Volatile => True);
end;
This Io_Write_32 implementation is not portable as we rebuilt the macro following the expansion tailored for arm64. A C wrapper would be less trouble while ensuring portability. Nevertheless, we felt this experiment was a good opportunity to show assembly directives in Ada.
I hope you appreciated this moderately dense overview of Ada in the context of Linux kernel module developpement. I think we can agree that Ada is a really disciplined and powerful contender when it comes to system, pedal to the metal, programming. I thank you for your time and concern. Do not hesitate to reach out and, happy Ada coding!
I want to thank Quentin Ochem, Nicolas Setton, Fabien Chouteau, Jerome Lambourg, Michael Frank, Derek Schacht, Arnaud Charlet, Pat Bernardi, Leo Germond, and Artium Nihamkin for their different insights and feedback to nail this experiment.

The author, Olivier Henley, is a UX Engineer at AdaCore. His role is exploring new markets through technical stories. Prior to joining AdaCore, Olivier was a consultant software engineer for Autodesk. Prior to that, Olivier worked on AAA game titles such as For Honor and Rainbow Six Siege in addition to many R&D gaming endeavors at Ubisoft Montreal. Olivier graduated from the Electrical Engineering program in Polytechnique Montreal. He is a co-author of patent US8884949B1, describing the invention of a novel temporal filter implicating NI technology. An Ada advocate, Olivier actively curates GitHub’s Awesome-Ada list.
For this three part series, we implemented a ‘pedal to the metal’ GPIO driven, flashing of a LED, in the context of a Linux kernel module for the NVIDIA Jetson Nano development board (kernel-based v4.9.294, arm64) in my favorite programming language … Ada!
You can find the whole project published at https://github.com/ohenley/adacore_jetson. It is known to build and run properly. All instructions to be up and running in 5 minutes are included in the accompanying front-facing README.md. Do not hesitate to fill a Github issue if you find any problem.
Disclaimer: This text is meant to appeal to both Ada and non-Ada coders. Therefore I try to strike a balance between code story simplicity, didactic tractability, and features density. As I said to a colleague, this is the text I would have liked to cross before starting this experiment.
led.ads (specification file, Ada equivalent to C .h header file) is where we model a simple interface for our LED.
with Controllers;
package Led is -- this bit of Ada code provides an interface to our LED
package C Renames Controllers;
type State is (Off, On);
type Led_Type (Size : Natural) is tagged private;
subtype Tag Is String;
procedure Init (L : out Led_Type; P : C.Pin; T : Tag; S : State);
procedure Flip_State (L : in out Led_Type);
procedure Final (L : Led_Type);
private
for State use (Off => 0, On => 1);
function "not" (S : State) return State is
(if S = On then Off else On);
type Led_Type (Size : Natural) is tagged record
P : C.Pin;
T : Tag (1 .. Size);
S : State;
end record;
end Led;
For those new to Ada, many interesting things happen for a language operating at the metal.
The top-level code story resides in flash_led.adb. Immediately when the module is loaded by the kernel, Ada_Init_Module executes, called from our main.c entry point. It first imports the elaboration procedure flash_ledinit generated by GNATbind, runs it, Init our LED object, and then setup/registers the delayed work queue.
with Kernel;
with Controllers;
with Interfaces.C; use Interfaces.C;
...
package K renames Kernel;
package C renames Controllers;
Wq : K.Workqueue_Struct_Access := K.Null_Wq;
Delayed_Work : aliased K.Delayed_Work; -- subject to alias by some pointer on it
Pin : C.Pin := C.Jetson_Nano_Header_Pins (18);
Led_Tag : Led.Tag := "my_led";
My_Led : Led_Type (Led_Tag'Size);
Half_Period_Ms : Unsigned := 500;
...
procedure Ada_Init_Module is
procedure Ada_Linux_Init with
Import => True,
Convention => Ada,
External_Name => "flash_ledinit";
begin
Ada_Linux_Init;
My_Led.Init (P => Pin, T => Led_Tag, S => Off);
...
if Wq = K.Null_Wq then -- Ada equal
Wq := K.Create_Singlethread_Wq ("flash_led_wq");
end if;
if Wq /= K.Null_Wq then -- Ada not equal
K.Queue_Delayed_Work(Wq,
Delayed_Work'Access, -- an Ada pointer
K.Msecs_To_Jiffies (Half_Period_Ms));
end if;
end;
In the callback, instead of printing to the kernel message buffer, we call the Flip_State implementation of our LED object and re-register to the delayed work queue. It now flashes.
procedure Work_Callback (Work : K.Work_Struct_Access) is
begin
My_Led.Flip_State;
K.Queue_Delayed_Work (Wq,
Delayed_Work'Access, -- An Ada pointer
K.Msecs_To_Jiffies (Half_Period_Ms));
end;
If you search the web for images of “NVIDIA Jetson Development board GPIO header pinout” you will find such diagram.
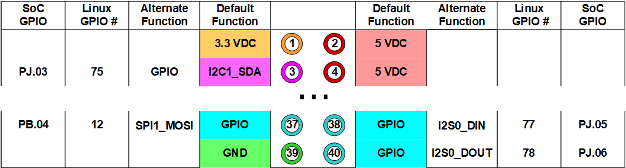
Right away, you figure there are about 5 data fields describing a single pinout
Looking at this diagram we find hints of the different mapping happening at the Tegra SoC, Linux, and physical pinout level. Each “interface” has its own addressing scheme. The Tegra SoC has logical naming and offers default and alternate functions for a given GPIO line. Linux maintains its own GPIO numbering of the lines so does the physical layout of the board.
From where I stand I want to connect a LED circuit to a board pin and control it without fuss, by using any addressing scheme available. For this we created an array of variant records instantiation, modeling the pin characteristics for the whole header pinouts. Nothing cryptic or ambiguous, just precise and clear structured data.
type Jetson_Nano_Header_Pin is range 1 .. 40; -- Nano Physical Expansion Pinout
type Jetson_Nano_Pin_Data_Array is array (Jetson_Nano_Header_Pin) of Pin_Data;
Jetson_Nano_Header_Pins : constant Jetson_Nano_Pin_Data_Array :=
(1 => (Default => VDC3_3, Alternate => NIL),
2 => (Default => VDC5_0, Alternate => NIL),
3 => (Default => I2C1_SDA,
Alternate => GPIO,
Linux_Nbr => 75,
Port => PJ,
Reg_Bit => 3,
Pinmux_Offset => 16#C8#),
4 => (Default => VDC5_0, Alternate => NIL),
...
40 => (Default => GPIO,
Alternate => I2S_DOUT,
Linux_Nbr => 78,
Port => PJ,
Reg_Bit => 6,
Pinmux_Offset => 16#14C#));
Because everything in this Jetson_Nano_Header_Pins data assembly is unique and unrelated it cannot be generalized further, it has to live somewhere, plainly. Let’s check how we model a single pin as Pin_Data.
type Function_Type is (GPIO, VDC3_3, VDC5_0, GND, NIL, ..., I2S_DOUT);
type Gpio_Linux_Nbr is range 0 .. 255; -- # cat /sys/kernel/debug/gpio
type Gpio_Tegra_Port is (PA, PB, ..., PEE, NIL);
type Gpio_Tegra_Register_Bit is range 0 .. 7;
type Pin_Data (Default : Function_Type := NIL) is record
Alternate: Function_Type := NIL;
case Default is
when VDC3_3 .. GND =>
Null; -- nothing to add
when others =>
Linux_Nbr : Gpio_Linux_Nbr;
Port : Gpio_Tegra_Port;
Reg_Bit : Gpio_Tegra_Register_Bit;
Pinmux_Offset : Storage_Offset;
end case;
end record;
Pin_Data type is a variant record, meaning, based on a Function_Type, it will contain “variable” data. Notice how we range over the Function_Type values to describe the switch cases. This gives us the capability to model all pins configuration.
When you consult the Technical Reference Manual (TRM) of the Nano board, you find that GPIO register controls are layed out following an arithmetic pattern. Using some hardware entry point constants and the specifics of a pin data held into Jetson_Nano_Header_Pins, one can resolve any register needed.
Gpio_Banks : constant Banks_Array :=
(To_Address (16#6000_D000#),
...
To_Address (16#6000_D700#));
type Register is (GPIO_CNF, GPIO_OE, GPIO_OUT, ..., GPIO_INT_CLR);
type Registers_Offsets_Array is array (Register) of Storage_Offset;
Registers_Offsets : constant Registers_Offsets_Array :=
(GPIO_CNF => 16#00#,
... ,
GPIO_INT_CLR => 16#70#);
function Get_Bank_Phys_Addr (Port : Gpio_Tegra_Port) return System.Address is
(Gpio_Banks (Gpio_Tegra_Port'Pos (Port) / 4 + 1));
function Get_Register_Phys_Addr (Port : Gpio_Tegra_Port; Reg : Register) return System.Address is
(Get_Bank_Phys_Address (Port) +
Registers_Offsets (Reg) +
(Gpio_Tegra_Port'Pos (Port) mod 4) * 4);
In this experiment, it is mainly used to request the kernel memory mapping of such GPIO register.
-- led.adb (raw io version)
Base_Addr := Ioremap (C.Get_Register_Phys_Address (Pin.Port, C.GPIO_CNF), Control_C'Size);
Now, let’s model a common Pinmux register found in the TRM.
package K renames Kernel;
...
type Bit is mod 2**1; -- will hold in 1 bit
type Two_Bits is mod 2**2; -- will hold in 2 bits
type Pinmux_Control is record
Pm : Two_Bits;
Pupd : Two_Bits;
Tristate : Bit;
Park : Bit;
E_Input : Bit;
Lock : Bit;
E_Hsm : Bit;
E_Schmt : Bit;
Drive_Type : Two_Bits;
end record with Size => K.U32'Size;
for Pinmux_Control use record
Pm at 0 range 0 .. 1; -- At byte 0 range bit 0 to bit 1
Pupd at 0 range 2 .. 3;
Tristate at 0 range 4 .. 4;
Park at 0 range 5 .. 5;
E_Input at 0 range 6 .. 6;
Lock at 0 range 7 .. 7;
E_Hsm at 0 range 9 .. 9;
E_Schmt at 0 range 12 .. 12;
Drive_Type at 0 range 13 .. 14;
end record;
I think the code speaks for itself.
You can now directly address bitfield/s by name and not worry about any bitwise arithmetic mishap. Ok so now what about logically addressing a bitfield/s? You pack inside arrays. We do have an example in the modeling of the GPIO register.
type Gpio_Tegra_Register_Bit is range 0 .. 7;
...
type Bit is mod 2**1; -- will hold in 1 bit
...
type Gpio_Bit_Array is array (Gpio_Tegra_Register_Bit) of Bit with Pack;
type Gpio_Control is record
Bits : Gpio_Bit_Array;
Locks : Gpio_Bit_Array;
end record with Size => K.U32'Size;
for Gpio_Control use record
Bits at 0 range 0 .. 7;
Locks at 1 range 0 .. 7; -- At byte 1 range bit 0 to bit 7
end record;
Now we can do.
procedure Set_Gpio (Pin : C.Pin; S : Led.State) is
function Bit (S: Led.State) return C.Bit renames Led.State'Enum_Rep;
-- remember we gave the Led.State Enum a numeric Representation clause.
Control : C.Gpio_Control := (Bits => (others => 0), -- init all to 0
Locks => (others => 0));
...
begin
...
Control.Bits (Pin.Reg_Bit) := Bit (S); -- Kewl!
...
end;
I had to give you a feel of what is to gain by modeling using Ada. To me, it is about semantic clarity, modeling affinity, and structural integrity. Ada offers flexibility through a structured approach to low-level details. Once set foot in Ada, domain modeling becomes easy because as you saw, you are given provisions to incisively specify things using strong user-defined types. The stringent compiler constraints your architecture to fall in place on every iteration. From experience, it is truly amazing how the GNAT toolchain helps you iterate quickly while keeping technical debt in check.
Ada is not too complex, nor too verbose; those are mundane concerns.
Ada demands you to demonstrate that your modeling makes sense for thousands of lines of code; it is code production under continuous streamlining.
In the last entry, we will finally meet the kernel. If I kept your interest and you want to close the loop, move here. Cheers!
I want to thank Quentin Ochem, Nicolas Setton, Fabien Chouteau, Jerome Lambourg, Michael Frank, Derek Schacht, Arnaud Charlet, Pat Bernardi, Leo Germond, and Artium Nihamkin for their different insights and feedback to nail this experiment.
The author, Olivier Henley, is a UX Engineer at AdaCore. His role is exploring new markets through technical stories. Prior to joining AdaCore, Olivier was a consultant software engineer for Autodesk. Prior to that, Olivier worked on AAA game titles such as For Honor and Rainbow Six Siege in addition to many R&D gaming endeavors at Ubisoft Montreal. Olivier graduated from the Electrical Engineering program in Polytechnique Montreal. He is a co-author of patent US8884949B1, describing the invention of a novel temporal filter implicating NI technology. An Ada advocate, Olivier actively curates GitHub’s Awesome-Ada list.
Learn how to process the output of shell commands within a script and send it to files, devices, or other commands or scripts.
Read More at Enable Sysadmin
Learn how to process the output of shell commands within a script and send it to files, devices, or other commands or scripts.
Read More at Enable Sysadmin
For this three part series, we implemented a ‘pedal to the metal’ GPIO driven, flashing of a LED, in the context of a Linux kernel module for the NVIDIA Jetson Nano development board (kernel-based v4.9.294, arm64) in my favorite programming language … Ada!
You can find the whole project published at https://github.com/ohenley/adacore_jetson. It is known to build and run properly. All instructions to be up and running in 5 minutes are included in the accompanying front-facing README.md. Do not hesitate to fill a Github issue if you find any problem.
Disclaimer: This text is meant to appeal to both Ada and non-Ada coders. Therefore I try to strike a balance between code story simplicity, didactic tractability, and features density. As I said to a colleague, this is the text I would have liked to cross before starting this experiment.
Delightfully said by Rod Chapman in his great SPARKNaCL presentation https://blog.adacore.com/sparknacl-two-years-of-optimizing-crypto-code-in-spark-and-counting, the Ada programming language is “Pascal on steroids”. Though, I would argue that the drug is healthy. Thriving on strong typing and packaging, Ada has excellent modelization scalability yet remains on par with C performances.
It compiles native object code using a GCC front-end or LLVM, respectively called GNAT and GNAT-LLVM. This leads us to an important reminder: Ada, at least through GNAT, has an application binary interface (ABI) compatible with C on Linux.
Note that as Ada code is not accepted in the upstream kernel sources and the Linux team made it clear it is not interested in providing a stable kernel API, writing Linux drivers shipped in Ada/SPARK mean you will have to adapt those drivers to all kernel version you are interested in, which is a task outside the scope of this document. For single kernel versions, proofs-of-concept, or organizations having enough firepower to maintain and curate their own drivers this is not an issue though.
Let’s discuss our overall driver structure from an orthodox C perspective. It will allow us to clear important know-how and gotchas. The following C kernel module (driver) implements a one-second delayed work queue repeatedly registering a callback writing “flip_led_state” to the kernel message buffer. Please, note the usage of the preprocessing macros.
/* printk_wq.c */
#include <linux/module.h>
#include <linux/workqueue.h>
#include <linux/timer.h>
void delayed_work_cb(struct work_struct* work);
struct workqueue_struct* wq = 0;
DECLARE_DELAYED_WORK(dw, delayed_work_cb); /* heavy lifting 1. */
void delayed_work_cb(struct work_struct* work)
{
printk("flip_led_state\n");
queue_delayed_work(wq, &dw, msecs_to_jiffies(1000));
}
int init_module(void)
{
if (!wq)
wq = create_singlethread_workqueue("my_wq"); /* heavy lifting 2. */
if (wq)
queue_delayed_work(wq, &dw, msecs_to_jiffies(1000));
return 0;
}
void cleanup_module(void)
{
if (wq){
cancel_delayed_work(&dw);
flush_workqueue(wq);
destroy_workqueue(wq);
}
}
MODULE_LICENSE("GPL");When building a kernel module on Linux the produced Executable and Linkable Format (ELF) object code file bears the *.ko extension. If we inspect the content of the working printk_wq.ko kernel module we can sketch the gist of binding to kernel module programming.
$ nm printk_wq.ko
...
U __alloc_workqueue_key
U cancel_delayed_work
00000000000000a0 T cleanup_module
0000000000000000 T delayed_work_cb
U delayed_work_timer_fn
U destroy_workqueue
0000000000000000 D dw
U flush_workqueue
0000000000000000 T init_module
U _mcount
0000000000000028 r __module_depends
U printk
U queue_delayed_work_on
0000000000000000 D __this_module
0000000000000000 r __UNIQUE_ID_license45
0000000000000031 r __UNIQUE_ID_vermagic44
0000000000000000 r ____versions
First, we recognize function/procedure names used in our source code eg. cancel_delayed_work. We also find that they are undefined (U). It is important to realize that those are the kernel’s source symbols and their object code will be resolved dynamically at driver/module load time. Correspondingly, all those undefined signatures can be found somewhere in the kernel source code headers of your target platform.
Second, we are missing some methods we explicitly called, eg. create_singlethread_workqueue, in the symbol table. This is because they are not, in fact, functions/procedures but convenience macros that expand to concrete implementations named differently and potentially have a different signature altogether or static inline not visible outside. For example, laying out the create_singlethread_workqueue explicit macro expansion from the Linux sources makes it clear. (Follow order, not preprocessor validation order)
/* https://elixir.bootlin.com/linux/v4.9.294/source/include/linux/workqueue.h*/
#define create_singlethread_workqueue(name) \
alloc_ordered_workqueue("%s", __WQ_LEGACY | WQ_MEM_RECLAIM, name)
...
#define alloc_ordered_workqueue(fmt, flags, args...) \
alloc_workqueue(fmt, WQ_UNBOUND | __WQ_ORDERED | \
__WQ_ORDERED_EXPLICIT | (flags), 1, ##args)
...
#define alloc_workqueue(fmt, flags, max_active, args...) \
__alloc_workqueue_key((fmt), (flags), (max_active), \
NULL, NULL, ##args)
...
extern struct workqueue_struct *
__alloc_workqueue_key(const char *fmt, unsigned int flags, int max_active,
struct lock_class_key *key, const char *lock_name, ...) __printf(1, 6);
Now everything makes sense. __alloc_workqueue_key is marked ‘extern’ and we find its signature in the printk_wq.ko symbol table. Note that we moved from create_singlethread_workqueue taking a single parameter to __alloc_workqueue_key taking more than five arguments. A logical conclusion, as deduced while following the explicit expansion up here, is that the arguments delta are all baked at the preprocessor stage. ‘Baking’ parameters using macros chaining offer polymorphism opportunities for kernel developers. Eg. compiling for arm64 may expand the macros differently than on RISC-V while offering both to retain a unified create_singlethread_workqueue(name) call for device driver developers to use; client of this ‘kernel API function’.
To get an Ada equivalent implementation of this driver I think of three choices when faced with a binding:
I will present an example of each in subsequent parts.
A Linux kernel module code structure is somewhat simple: you implement an init function, a deinit function. You have other requirements like supporting code reentry (eg. entering function may be called many times asynchronously) and you should not stall (eg. you do not run a game loop inside any kernel driver function). Optionally, if you are doing a platform (subsystem) driver, you need to register callbacks to polymorph a kernel interface of your choice. There is more to it, but you can get a long way just within this structure.
If you were to replace the shipped GPIO platform driver on your target machine, without breaking anything, your driver code would need to provide a concrete implementation of methods exposed in the linux/gpio/driver.h API. Below is some Tegra GPIO platform driver implementation code. If you start from the end, subsys_initcall(tegra_gpio_init), you should find that registering the driver sets a probe callback, in turn setting tegra_gpio_direction_output as the gpio_chip direction_output concrete code.
/* linux/gpio/driver.h */
struct gpio_chip {
int (*direction_output)(struct gpio_chip *chip,
unsigned offset, int value);
}
/* drivers/gpio/gpio-tegra.c */
struct tegra_gpio_info {
struct gpio_chip gc;
};
static int tegra_gpio_direction_output(struct gpio_chip *chip,
unsigned offset, int value)
{
...
return 0;
}
static int tegra_gpio_probe(struct platform_device *pdev)
{
tgi->gc.direction_output = tegra_gpio_direction_output;
}
static struct platform_driver tegra_gpio_driver = {
.probe = tegra_gpio_probe,
};
static int __init tegra_gpio_init(void)
{
return platform_driver_register(&tegra_gpio_driver);
}
subsys_initcall(tegra_gpio_init);
subsys_initcall is used to build statically linked module only and serves to implement platform driver. init_module can be used to init a built-in or loadable module but subsys_initcall is guaranteed to be executed before init_module. For this experiment we implemented a device driver making use of init_module.
To step into an Ada implementation we needed to concede by creating our driver entry point in C first.
From there we extern the ada_init_module and ada_cleanup_module function where we will pick up, fully Ada, to implement the delayed work queue structure seen previously and all consequent modeling of our flashing led driver.
/* main c */
#include <linux/module.h>
extern void ada_init_module (void);
extern void ada_cleanup_module (void);
int init_module(void)
{
ada_init_module();
return 0;
}
void cleanup_module(void)
{
ada_cleanup_module();
}
MODULE_LICENSE("GPL");
If you compile the following C code using your default Linux desktop compiler toolchain
STR="void main(){}" && echo -e $STR | gcc -o output.o -xc -And inspect its symbol table
$ nm output.o
...
0000000000400510 T __libc_csu_init
U __libc_start_main@GLIBC_2.2.5
00000000004004f6 T main
U printf@GLIBC_2.2.5
...
You find references to libc you did not explicitly ask for. You need the heads-up that those undefined (U) won’t be resolved at kernel module loading. A lot of libc implements stuff at the userspace level which is not compatible with the kernel operations so it is forbidden altogether.
Using system default GCC, make calling Kbuild using a special syntax, Kbuild will automatically strip those dependencies to libc for you to produce a valid kernel module (*.ko). But what happens when you link object code ‘compiled as usual’ from another rich and complex language like Ada to your kernel module? The object code will most certainly contain machinery from the language runtime, complex routines that end up tapping in libc, or other forbidden operations in the kernel context. This is where you need a constrained, reduced runtime for your language of choice.
What is cool with Ada though is that the GNAT infrastructure has runtime separation architectured to be swapped. Using AdaCore codebases, you can build your runtime by embarking on just what you want/need in it to link against. GNAT Ada runs on countless barebone platforms so the runtime granularity and dependency problems have already, most of the time, been handled for you. To initialize this runtime properly you are given sensible control on where and when to run some elaboration code; more on that later when we cover the Ada side of things.
For this experiment, we built a light aarch64-linux native runtime compatible to run in kernel space while retaining convenient aspects of the language, eg. the secondary stack. Using the https://github.com/AdaCore/bb-runtimes scripts, we augmented a new target aarch64-linux and built the runtime. Getting to know ‘how to do’ took longer, building it takes seconds. You can find and use this runtime in the experiment repository under rts-native-light/ when cross compiling using GNAT Pro. If you are building using the platform GNAT FSF the runtime is found under rts-native-zfp/?.
Kbuild is somewhat flexible so GNAT object code can be linked into the kernel driver without too much effort. As implied previously, make understands syntax to leverage and activate Kbuild, eg. to produce our driver called flash_led.ko, start from transient flash_led.o that depends on obj/bundle.o to build. Our module makefile uses this special syntax
obj-m := flash_led.o
flash_led-y := obj/bundle.o
You can ‘trick’ Kbuild/make by providing already existing .o files as long as you also provide dependable *.o.cmd intermediary files to Kbuild. We leverage such substitution by coordinating GPRbuild (GNAT build system), Kbuild/make, and touch using Python. There are two phases, generate and build.
$ python make.py generate config:flash_led_jetson_nano.json1. Build, in the background, a bare minimum known to be valid main_template.c kernel driver and extract the compilation switches used by make/Kbuild to successfully produce this main_template.ko guinea pig module. There are around ~80 such GCC switches captured and used to generate the basic, valid *.ko for this kernel-based v4.9.294, arm64 platform. This ‘buried deep into Kbuild’ knowledge extraction turned out to be key in stabilizing the production of valid kernel object code. Note that this trick should work well for any platform because it extracts its specifics.
2. Generate the GPRbuild project file injecting those ~80 switches for the compilation of our project main.c along with all Ada source files using different project configuration data found in the JSON file.
3. Generate Makefile using knowledge of configuration data compliant with Kbuild syntax (cross compiler location, project name, etc found in the JSON file).
You can inspect the different templates and their substitution markers eg. <replace_me_token> by looking inside the template folder of the project repository.
python make.py build config:flash_led_jetson_nano.json rts:true1. Build the GNAT runtime library (RTS) libgnat.a by driving its runtime_build.gpr project file. (optional on subsequent passes)
2. Build our driver project standalone library libflash_led.a using the generated GPRbuild project file.
3. Link our custom RTS libgnat.a with our project libflash_led.a to a tidy bundle.o object.
4. Create missing *.o.cmd intermediary files to keep Kbuild happy. Remember we are swapping already built objects under its nose!
5. Finally, launch the makefile to cross-compile our flash_led.ko driver for the Jetson Nano aarch64 platform!
For this experiment we did two implementations of Led.adb (body file, Ada equivalent of C .c source file), one at src/linux_interface/led.adb, the other under src/raw_io/led.adb. You specify which driver implementation you want to build by setting “module_flavor” value in flash_led_jetson_nano.json. make.py will inject the proper source paths in the project driver flash_led.gpr file during the generate phase.
The first version implementation of the LED interface binds to standard kernel API Gpio_Request, Gpio_Direction_Output, Gpio_Get_Value, and Gpio_Free functions exposed in include/linux/gpio.h. This is rather straightforward as the binding is mostly one-to-one to the C functions. In this linux_interface version, as soon as you bind, you end up executing the C concrete implementation of the shipped GPIO driver.
Circumventing most Linux machinery, the second raw_io version implementing the LED interface is more interesting as we control the GPIO directly by writing to IO memory registers. Akin to doing bare-metal, directly driving GPIOs is a matter of configuring some IO registers mapped in physical memory. Remember an OS serves the role of a hardware orchestrator and consequently acts as having implicit ownership over your hardware. To tap directly onto physical memory in a kernel context often requires some kind of red tape crossing.
Here Linux requires (strongly suggests?) you write/read to kernel mapped memory instead of directly to physical memory. First, you need to acquire the kernel-mapped physical address using the in/famous ioremap call. Using the mapped address we read and write to our GPIO registers using ioread32 and iowrite32 respectively. This is the only Linux machinery involved in this raw_io version. As you probably figure this is more a peek at what one would code inside a driver responsible to implement the concrete implementations of functions offered by something like include/linux/gpio.h. We will even end up writing assembly code from Ada to achieve pure rawness!
I had to set the table to write Linux kernel modules in Ada by first talking about C, object code, Kbuild, constrained runtime, and overall build strategy. The streamlined fun begins as we cross the Ada fence. If I picked your curiosity and you are ready to dig Ada, meet me here. Cheers!
I want to thank Quentin Ochem, Nicolas Setton, Fabien Chouteau, Jerome Lambourg, Michael Frank, Derek Schacht, Arnaud Charlet, Pat Bernardi, Leo Germond, and Artium Nihamkin for their different insights and feedback to nail this experiment.
The author, Olivier Henley, is a UX Engineer at AdaCore. His role is exploring new markets through technical stories. Prior to joining AdaCore, Olivier was a consultant software engineer for Autodesk. Prior to that, Olivier worked on AAA game titles such as For Honor and Rainbow Six Siege in addition to many R&D gaming endeavors at Ubisoft Montreal. Olivier graduated from the Electrical Engineering program in Polytechnique Montreal. He is a co-author of patent US8884949B1, describing the invention of a novel temporal filter implicating NI technology. An Ada advocate, Olivier actively curates GitHub’s Awesome-Ada list.
Pdb is a powerful tool for finding syntax errors, spelling mistakes, missing code, and other issues in your Python code.
Read More at Enable Sysadmin
{kind=link}
{kind=link}
{kind=link}
{kind=link}