
In the never-ending quest to do more with less, IT departments are always looking for ways to save money without sacrificing the high availability, performance and security needed in business-critical enterprise applications. When Microsoft began supporting SQL Server on Linux in 2017, many organizations considered migrating to this open source operating system in both private and public clouds. But they quickly discovered that some essential capabilities available in a Windows environment were not yet supported on Linux.
One of the most challenging of these issues involves ensuring high availability with robust replication and automatic failover. Most Linux distributions give IT departments two equally bad choices for high availability: Either pay more for SQL Server Enterprise Edition to implement Always On Availability Groups; or struggle to make complex do-it-yourself HA Linux configurations work well—something that can be extraordinarily difficult to do.
This unsatisfactory situation has given rise to some new, third-party high availability solutions for SQL Server applications running in a Linux environment. But before discussing these new solutions, it is instructive to understand more about the two current choices.
The problem with using Enterprise Edition is rather apparent: It undermines the cost-saving rationale for using open source operating system software on commodity hardware. For a limited number of small SQL Server applications, it might be possible to justify the additional cost. But it’s too expensive for many database applications and will do nothing to provide general-purpose HA for Linux.
Providing HA across all applications running in a Linux environment is possible using open source software, such as Pacemaker and Corosync, or SUSE Linux Enterprise High Availability Extension. But getting the full software stack to work as desired requires creating (and testing) custom scripts for each application, and these scripts often need to be retested and updated after even minor changes are made to any of the software or hardware being used. Availability-related capabilities that are currently unsupported in both SQL Server Standard Edition and Linux can make this effort all the more challenging.
To make HA both cost-effective and easy to implement, the new solutions take two different, general-purpose approaches. One is storage-based systems that protect data by replicating it within a redundant and resilient storage area networks (SANs). This approach is agnostic with respect to host operating system, but it requires that the entire SAN infrastructure be acquired from a single vendor and relies on separate failover provisions to deliver high availability.
The other approach is host-based and involves creating a storage-agnostic SANless cluster across Linux server instances. As an HA overlay, these clusters are capable of operating across both the LAN and WAN in private, public and hybrid clouds. The overlay is also application-agnostic, enabling organizations to have a single, universal HA solution across all applications. While this approach does consume host resources, these are relatively inexpensive and easy to scale in a Linux environment.
Most HA SANless cluster solutions provide a combination of real-time block-level data replication, continuous application monitoring, and configurable failover/failback recovery policies to protect all business-critical applications, including those using Always On Failover Cluster Instances available in the Standard Edition of SQL Server.
Some of the more robust HA SANless cluster solutions also offer advanced capabilities, such as ease of configuration and operation with an intuitive graphical user interface, a choice of synchronous or asynchronous replication, WAN optimization to maximize performance, manual switchover of primary and secondary server assignments for planned maintenance, and performing regular backups without disruption to the application.
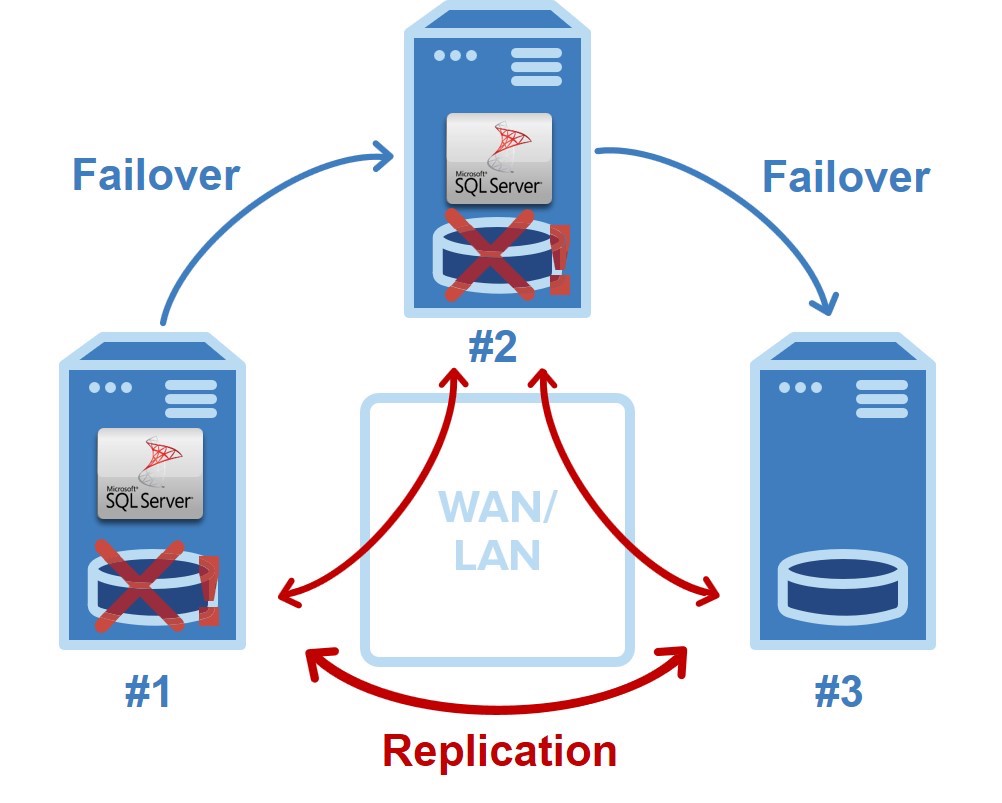
A three-node SANless cluster with two concurrent failures
The diagram above shows how a SANless cluster is able to handle two concurrent failures. The basic operation is the same in the LAN and WAN, as well as across private, public and hybrid clouds. Server #1 is initially the primary that replicates data to both servers #2 and #3. It experiences a problem, automatically triggering a failover to server #2, which now becomes the primary replicating data to server #3.
In this situation, the IT department would likely begin diagnosing and repairing whatever problem caused server #1 to fail. Once fixed, it could be restored as the primary or server #2 could continue in that capacity replicating data to both servers #1 and #3. Should server #2 fail before server #1 is returned to operation, a failover would be triggered to server #3.
With most HA SANless clustering solutions failovers are automatic, and both failovers and failbacks can be controlled by a browser-based console. This ability enables a 3-node configuration like this one to be used for maintenance purposes while continuously providing high-availability for the application and its data.
Michael Traudt, SIOS Technology Senior Solutions Architect, brings 16 years of experience in high availability, DR, and backup and recovery. Focused on tier one application use cases he has hands-on experience building environments from the ground up based on needs to demonstrate applied features, run performance and scalability testing, or collect competitive analysis metrics.




